With a big thud another well used educator web site not only bites the dust but totally poops the web.
Just after publishing the newest version of Another Web Bites the Dust, the first tweet in my mention us this:
Next update: Wikispaces 🙁#edTech
— Ismael Peña-López (@ictlogist) February 14, 2018
No, not Wikispaces! I’ve used the hosted wiki service since their start in 2005. I think I first dabbled in PBWiki (which was once cutely known as “making a wiki is as easy as making a peanut butter sandwich” but now seems to be some corporate collaboration store front).
Wikispaces was the backbone for my 2007 trip down under, the first home of 50 Web 2.0 Ways to Tell a Story and more. There was one hoisted in 2008 as an appendix for the Web-Based Storytelling article I published with Bryan Alexander. I’ve used it since 2012 to house my various presentations and associated resources and another one to host more wiki-based presentations. 50+ web Ways to Tell a Story got a reboot/refresh as its own wikispace in 2010. I got NMC set up with hosted Wikispaces for the Horizon Project work and more from 2008 on (who knows what will happen to their archive).
All of those links will be flushed down the web sewer hole in July. All of the places linking to them from elsewhere on the web will spawn dead link errors.
Over the last twelve months we have been carrying out a complete technical review of the infrastructure and software we use to serve Wikispaces users. As part of the review, it has become apparent that the required investment to bring the infrastructure and code in line with modern standards is very substantial. We have explored all possible options for keeping Wikispaces running but have had to conclude that it is no longer viable to continue to run the service in the long term. So, it is with no small degree of nostalgia, that we will begin to close down later this year.
Notice how they make no effort to contribute the content to the Internet Archive. They do not make at least the effort to preserve existing content as static.
Nope, just cut us all off.
Oh we get such great options for export.
You can export or download your data by following the steps below. Please note that this will download in Wikispaces Format and, if you are planning to upload this onto another site you may find it easier to copy and paste the data from directly your Wiki to your new chosen Wiki site. Please keep this in mind and allow yourself enough time to do this.
Let me translate this for you- their exports are useless unless you want to cut and paste and reformat content. The export suggest exports for various wiki platforms (WikiMedia, DocuWiki, etc), but they are not importable data files (XML), they are just individual static wikitext.
What’s even worse, because of their session authentication, despite seeing traces of them in the Internet Archive, the Wayback machine just tosses you in a cycle of redirects.
No Wayback Machine path for Wikispaces. Bad Wiki.
I spent a good chunk of time last night seeing what I could do with their export. Here is the view of 50+ Ways as it stands now at http://50ways.wikispaces.com/ (link dies July 31, 2018, RIP)
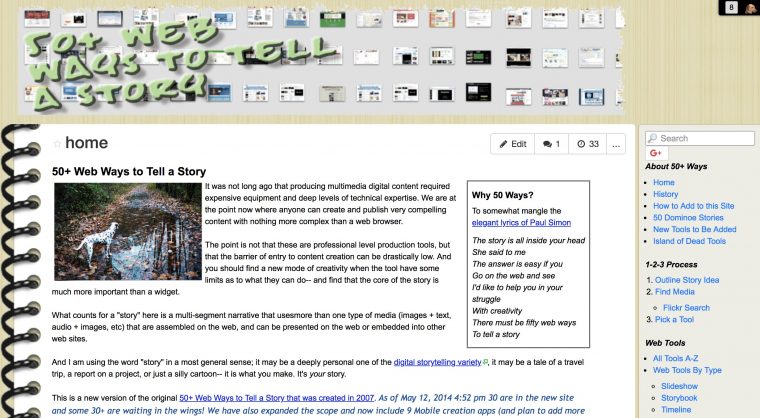
The dying corpse of a 11 year old Wikispaces project
The HTML export gives you all of the content as separate pages, but unless you have internal links on the front, you are SOL because the navigation sidebar is gone. This is the export of the same wiki
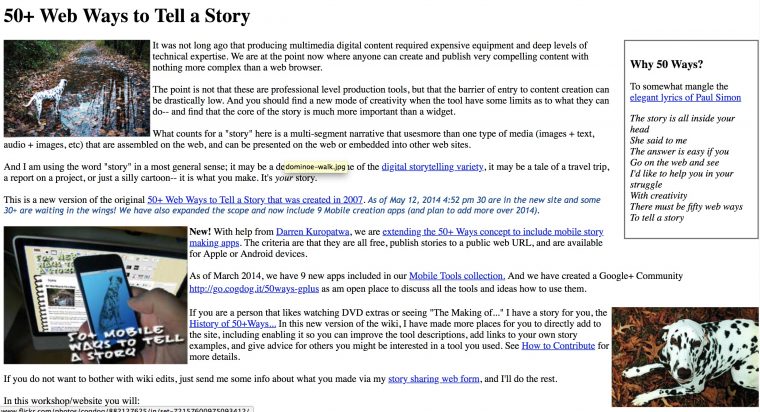
The HTML export of the 50+ Ways wikispaces site
It’s more or less all the content, sans format. I guess it’s not horrible (I still had to do some global search and replaces to convert internal links that were absolute URLs).
However I was determined to see if I could do a better archive job, so I turned to my trusty SiteSucker app.
The first “suck” got me like 3000 files. But the first problem I noticed was that they were using URLs to Wikispaces for CSS, Javascript, and more. I toggled the setting in SiteSucker to download those apps, but it kept crashing (Wikispaces is blocking requests).
So I went back to the other one, and started downloading local versions of all JavaScript and CSS files, plus images used in CSS. I ran about 35 search and replaces cross the entire directory (Thank you BBEdit, you are my lavation again). There were still a lot of un-necessary menu bars, wiki editing tools, and I opted to hide them by adding some CSS display:none for divs that contained the top menu bar, the wiki edit stuff.
This was added at the bottom of the embedded CSS to hide the Wikispace chrome:
.ws-theme-header .ws-theme-menu-inner, .WikiInternalHeaderNav, .WikiFooterNav.WikiElement, .btn-group.pull-right {
display: none!important;
}
I did global search and replace to clean the footer and toss some shame at Wikispaces. F*** them.

Thanks for nothing, Wikispaces
More regex search and replace over 1000 files to fix URLs. It’s likely still got problems, but I find the CogDog Archived version much more palatable that the export they crapped out:
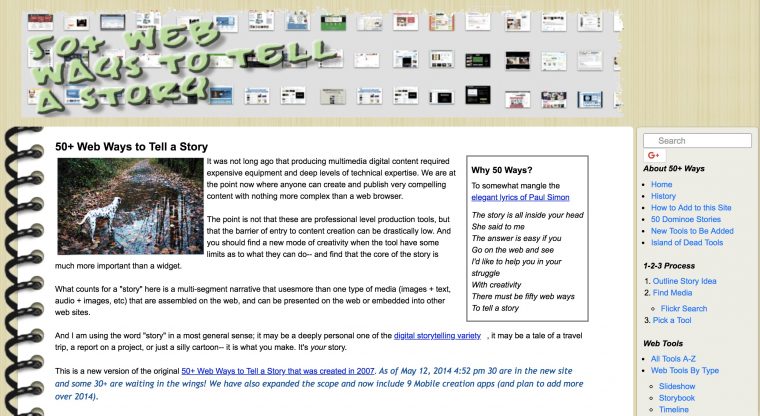
My site sucked and manually cleaned archive of the 50+ Ways site
This was heinous stupid, tedious work to do. Yeah, I am guilty of expecting forever hosting of free stuff. But for some reason, maybe because Wikispaces was there so long, that maybe even if they folded, they would do so gracefully, and thinking of preserving the legacy of content created there.
And often I justified it by saying that its worth it to use the kinds of tools teachers might do. Hell yes, I can build my own sites and wikis. But I felt like this was some talk walking.
Hah.
So let’s be frank. Any company offering you a free web based service, no matter how smarmy their mission statement about making the world better, does not give a rats turd about your content. They will flush you at the drop of a dime. A penny.
There are so many ways Wikispaces could have done this gracefully (and their front page is still offering services like it’s same as it every was). They could have done something to maintain legacy content as static HTML. Or turned it over to the experts at the Internet Archive. Did they even communicate this problem to their so-called “community”? This stuff is valuable to many of us, and I would have been willing to pay to keep my wiki’s alive.
I didn’t even get an email notification.
Nope, they just flushed the tank. There go your wikis and mine. Swirling down the not found hole
This one is a big turd going down the hole.
Wikispaces is going front and poop center for the next video update:
Featured Image: 60073 Service Truck flickr photo by Brickset shared under a Creative Commons (BY) license modified by slapping a Wikispaces logo on the smelly port-a-potty.

It is a nice time that you had more success than I did. I tried doing their Export to HTML and it didn’t give me any of the menus to tie it all together. And because UNCLE @jimgroom said a thing today about Sitesucker, I downloaded it and tried that too but it just got borked with just one page that was an error message. Maybe I will try it again after a mission.
But you are right it is a poopy time with Wikispaces doing that thing because I probably have about 14 sites when I logon that I belong to and they will all disappear into the dust of world-wide cobwebs.
Poop. Dust. Cobwebs.
But I didn’t see a link this evening to a guy who has made a dog Poo composter that makes gas for his nightlight and barbecue.
http://www.bbc.com/news/uk-england-hereford-worcester-42565633
Yes, SiteSucker borked with the Webpage settings set to “In Supporting Files” – if you check the error log you will see it’s because Wikispaces is refusing access to js / css files. That’s why I had to do a bunch of search and replace after manually downloading, to change reference to remote css/js files to local versions.
@iamTalkyTina – look for the files ‘home.html’ and ‘space.menu.html’. The first one is your wiki’s index page and the second is the menu system. You could merge them, or use DIV’s to merge them and have it look similar to Wikispaces.
The same week I decommissioned wiki.ucalgary.ca (after 13+ years). Not a good week for wikis. I did leave a full static clone of the wiki in place for reference – pulled down via wget rather than SiteSucker). Running servers forever is hard.
I remember a wiki there that Dave Cormier setup where we were brainstorming a “server commune” and Hippie Hosting was born of that (It was at http://servercommune.wikispaces.com/ which doesn’t even appear to be online anymore). Shame to see it all go.
I don’t expect every single shred we put up to be preserved, but at least make some kind of genuine effort besides allusion to some hand wringing internal meeting. They did not communicate or ask their community to help. The are closing the door on paying customers. Is it really unfeasible to offer running a wget and asking us if we’d like to pay to keep our content online at the urls they were created? Just giving a shitty export file is not doing much at all.
They did not seem to consider the move that a small organization like ITConversations was above to do- move their content to the Internet archive, and then set up a server to redirect traffic.
> Not a good week for wikis.
Sad news indeed from Wikispaces. 🙁
There is, however, now a migration service available from CIviHosting here:
https://civihosting.com/wikispaces-migration/
We are providing this service, at a small fee, to allow ex-Wikispaces users to salvage their wikis and keep them online and editable.
Interesting, and a lot of work.
But if you just want a static HTML site for archival reasons it’s easier to just use Wikispace’s built-in HTML export, unzip the file and dump it to a directory on your server, and then create a nice little index page with a menu and a search and you’re done. You don’t ‘need to search and replace and change links in each page, etc.
I come up with another method of importing the Wikispaces exports directly into a WordPress installation after playing with the data a bit, and now I have a test ‘wiki’ set up with all of my 880+ pages of wiki content in a nice little WordPress installation.
BTW, here’s the test URL of the static site I set up by just exporting our wiki in HTML – http://hmienterprises.com/jeffcowiki/Jefferson%20County.html It needs an index page and search but works fine on it’s own without any extra if needed.
Here is a test conversion I did using WordPress, a plugin, and the HTML export from Wikispaces – http://oabonny.com/jeffcowiki/
That looks cool, Marc, curious how the wordpress approach was done. I was told by the developer of the SiteSucker app that the reason my attempt failed was because I’m running an older OS and not the latest version.
I think I am going to post a blog entry about the process, a quick over view, I’ll let you know when I finish it.
Here’s my blog post about using WordPress and a plugin to convert a Wikispaces HTML export to WordPress – http://randombitsbytes.com/migrating-wikispaces-content-to-wordpress/
Thanks so much for sharing this, Marc. I hope to give it a try, and will at least make sure I get all my exports done before Wikispaces chopping days.
They already shut our’s down, they wanted another year’s subscription price just to keep it running to the overall shutdown in July.
More than unhelpful–export system broke or something. It looks like it’s exporting, but redirects to an error page once export is complete. No way to get the exports listed on the Settings page. “No file” and other error messages ensue. I have a help ticket in, but not holding my breath.
That’s crappy on top of crappy!