In theory, their motto is about not doing evil, but Google sure does some smelly things that we can only guess at because of their opaqueness. Like giving favorable image search results to sites that obviously scrape content from other sites and serve it up as shoddy copies.
I do a lot of searching of Google Images using the filters for results that are open licensed. I have serious questions about the ordering of results.
Like what?
I forget now the keywords, but this came up within the first fold of results, at this URL http://maxpixel.freegreatpicture.com/Boy-Camera-Baby-Child-Street-Kids-Hat-Kid-City-2863615

Now jusy make a simple domain swap to https://pixabay.com/Boy-Camera-Baby-Child-Street-Kids-Hat-Kid-City-2863615/.

Do you notice anything similar? Same picture. Almost the same layout. Even the favicons are similar. But if you have a keen eye, you will notice on the maxpixel site:
- There is no credit given to the photographer (in the top right of the pixabay version)
- Notice a lack of a link on maxpixel for Creative Commons. Nada
- The awkward language below the photo “Our team was selected carefully before publish at here . If it is helpful to you, please share with your friends.”
I see this rampant in image search results- high placement for images from maxpixel above the ones from pixabay. You do not need a fancy degree to see that this site is scraping content from pixabay. You can say on a legal hair that they are not stealing because the photos are public domain. That’s not the issue.
But look at those sites side by side. How does the great Google AI not see the duplication?
I can’t find any info on the domain freegreatpicture.com besides it’s registration with Namesilo.com — at least the registration for pixabay.com is a German company which aligns with the info on their site.
From their primary domain, I learn there is a “Mr Bang” and friends behind this:
We are a group that includes many members, associates specializing in graphic design scattered all over the world. All are focused freegreatpicture.com construction site, with the aim of providing users tens of thousands of pictures, wallpapers and designs of high quality.
Very rich category, vivid color, beautiful image, it will bring you more emotional.
It does not say that they scrape the rich category, vivid color, beautiful images from other sites.
But the practice gets even more creepy when you see your own photos scraped to other image farms, and their results rank higher than the originals.
I did a Google image search (results filtered licensed for reuse) on the word “juxtaposition”. I recognized two photos in the results that are mine, except they are coming from pxhere.com

Two of my own photos that are on flickr, show up in results
Here is one of the originals, from my flickr account:

Dog Blues flickr photo by cogdogblog shared under a Creative Commons (BY) license
It’s licensed CC BY (one of a bunch that did not get batch converted to CC0, that’s a story for another day). The thing is, all the photos on pxhere.com are licensed CC0. While they can reuse by image, they cannot do so without attribution nor can they change the license.
So I let them know.
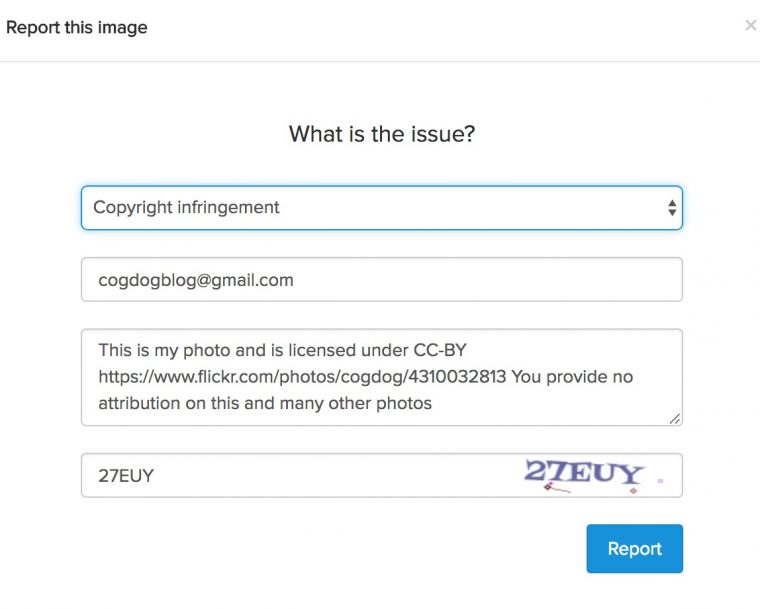
Reporting my own photo!
I never heard back, but the photo is gone from pxhere.com. A nano victory.
So for comparison, here is a comparison again, one of my original photos (CC0)

Here is the same photo on pxhere.com that gets returned as a higher ranked result in Google Images:

The major difference is it gives me no credit nor links to my original. But that’s not the problem, since I licensed it CC0, which 99.999999% of people explain as “That means you can use it without giving attribution”
And yes, re-use here means that people can set up large image farms of other people’s images. That’s all legit. I do not argue with that.
What I think odd is the higher placed the scraped photos are over the original.
The reason is actually simple– metadata, SEO drenched soaked keywords.
You do not understand by comparing the images on the web page, you compare by looking at the source code. This is the IMG tag for my original photo on flickr:

Now look how many keyword have been added to my photo in the source code for the same image on pxhere.com

The lesson is that Google is not searching images, it is searching metadata. It thinks and acts like an algorithm. And algorithms are gamed.
I’ve wondered about switching my methods… I like using the google search because I can use their modifiers, and I can get results from Wikimedia Commons, flickr, and pixabay (my usual sources). But it bothers me that Google gives higher preference to scraper sites that sprinkled photos with metadata, or worse, just wholesale lift copies of content from legitimate sites.
Not evil, but not very human.
Featured Image: I did a Google image search for “thief” with options for results that are licensed for reuse. As usual, I see results from the site http://maxpixel.freegreatpicture.com/ such as this one that are obvious thefts of the ones at pixabay (just switch the domain to the source).
Original Pixabay (not Maxpixel) photo by annawaldl placed into the public domain using Creative Commons CC0.

The value add of being able to search from a central point includes the algorithms (secret sauce) GoogleCo sprinkle on it. It would be nice to be able to strip that secret sauce back off and just get the results, without the gamed metadata al-GO-riddums.
Yes, this is the problem with Google. It’s search algorithm is messed up. I’ve seen many scraper sites ranking up top even for text search results.