I’m back in the podcast editing saddle with two sessions parked in Audacity for the OEG Voices show and hoping I can pin Antonio Vantaggiato down (or get my own schedule in order) for an overdue Puerto Rico Connection episode.
But there is ummmm, something that I have ummmm, being pondering.
To me, a universal law of audio editing is, “Everyone hates the sound of their own voice.” And mine is, as I hear my own tracks, the frequency of my use of “ummm.” I can easily look at my waveform and see them. My editing is pretty much a meticulous replay where I remove my own “umms” and those of my guests.
But I also end up nipping what seems to me as extraneous dead space between spoken parts and when I hear intakes of breaths. At a minimum, taking them out can tighten up the length of a show, right?
I was even saving a file of the deleted ummms, mine and from my guests, this is either fun or weird:
And just to prove the unexpected nature of twitter, where your most crafted thoughtful insightful bit of tweetage goes ignored, and a toss off tweet like this generates more ripples than I have seen in a while.
As always, wise, experienced advice from my friend, colleague with the impressive radio voice:
It got interesting quickly
I had never come across this concept, but it makes sense, the use if “umm” conversationally as a filler, to keep the flow going to signal you have not completed the thought your brain is sending to your mouth:
Suppose you are having trouble formulating your next phrase: If you go silent, the other person may figure that you have finished your turn at talking, and they may take over the line of conversation. If this happens, you have potentially lost your thread forever, as the conversation goes in an unpredicted new direction. So, if you are temporarily delayed and are intending to continue, it makes good sense to use a filler like um or uh. The filler is a traffic signal that accounts for your delay: “Please wait a moment, I’m not done yet, normal transmission will soon resume.” If the other person is cooperating, as people usually are, they will refrain from taking over the floor.
Despite the fact that fillers like um and uh have clear functions in conversation, we are often told to avoid them. The problem is that, in informal conversation at least, if you were to eliminate all of your ums and uhs, you would find people assuming you had finished your turn, and they would start speaking when you weren’t actually done yet.
https://qz.com/work/1175505/a-linguist-explains-why-its-okay-to-say-um-and-uh/
As a sidelight, this affirming response was a true reward
Sidenote: Amber was a UMW student of mine long ago for DS106, Spring 2013 I believe, and even then she came with audio chops having done voices for a YouTube cartoons. I was able to DM her and learned she is now doing voice work in Hollywood, so she made it (and I cannot take any credit, she was an amazing student)
More research came in (I see this and can still love twitter)
That link has already vanished (it must have been there as I have it saved as a PDF), but the Research Gate entry offers the citation and abstract:
The proposal examined here is that speakers use uh and um to announce that they are initiating what they expect to be a minor (uh), or major (um), delay in speaking. Speakers can use these announcements in turn to implicate, for example, that they are searching for a word, are deciding what to say next, want to keep the floor, or want to cede the floor. Evidence for the proposal comes from several large corpora of spontaneous speech. The evidence shows that speakers monitor their speech plans for upcoming delays worthy of comment. When they discover such a delay, they formulate where and how to suspend speaking, which item to produce (uh or um), whether to attach it as a clitic onto the previous word (as in “and-uh”), and whether to prolong it. The argument is that uh and um are conventional English words, and speakers plan for, formulate, and produce them just as they would any word.
Clark, Herbert & Fox Tree, Jean. (2002). Using uh and um in spontaneous dialog. Cognition. 84. 73-111. 10.1016/S0010-0277(02)00017-3.
Ah, research! My ums have meaning, purpose, and I can even glom on to the assertion “The argument is that uh and um are conventional English words, and speakers plan for, formulate, and produce them just as they would any word.“
Woah.
Another paper by the same author, and it’s gobsmacking to find a publisher link I can actually read the whole paper– see Listeners’ uses of um and uh in speech comprehension
Despite their frequency in conversational talk, little is known about how ums and uhs affect listeners’ on-line processing of spontaneous speech. Two studies of ums and uhs in English and Dutch reveal that hearing an uh has a beneficial effect on listeners’ ability to recognize words in upcoming speech, but that hearing an um has neither a beneficial nor a detrimental effect. The results suggest that um and uh are different from one another and support the hypothesis that uh is a signal of short upcoming delay and um is a signal of a long upcoming delay.
https://link.springer.com/content/pdf/10.3758%2FBF03194926.pdf
More research I should lean on- as much as my umms may make me cringe, I can relax because Fox Tree’s paper suggests that “hearing an um has neither a beneficial nor a detrimental effect.”
The other thing that has been working away at my brain is a bit of wonder that if my zeal to clean up bits between the words of my guests, and also to remove the gaps between their words– am I actually changing their natural speech pattern? Some people just speak with more — deliberate — pauses and maybe its not just “dead air” but their natural speech. Who am I to “clean”.
So what I am coming away with is that maybe I can a whole lot less nitty gritty editing… and also not feel like my own ummmage is negative. It must be how I speak because the machine records how I speak, and is a much better source of data than the imaginary bird in my head who thinks they know how I sound.
One more nugget came in the twitter replies… again, this serendipity at it’s tweeted best
As a long time listener of NPR’s Fresh Air show hosted by Terry Gross (I listened to this much when I lived in the states and usually had NPR on all day), Steve noticed one segment that jumped out for having an excess of “filler words” “breaths and stammers” the kind of stuff I have been editing out.
I sampled the question and answer and gave it my “close editing” treatment of removing unattached filler words, stammers, and breaths. This means that words such as “um,” “like,” “ah,” etc. are snipped out if they are not attached to other utterances. Likewise, I removed noticeable breaths if they were unattached to other utterances. This method leaves plenty of repeated words, and filler sounds such as “uh,” “ah,” and “um.” Removing these completely would make the speech sound robotic. Removing these samples when they stand alone (e.g. with silence before and after them) leaves a natural yet polished sounding spoken prose that feels authentic, provided enough silence is left where the omissions are made.
Terry Gross Editing Exercise
Steve feels the editing made it feel natural and human but still unsure if it’s really an improvement. “It seems arrogant and silly to attempt to “improve” what goes on the air for that program.” His Google drive link includes the two versions so you can compare.
If ever I teach audio editing again, I might introduce an exercise like this, so students can practice doing tight edits but also do some testing to assess what kind of difference “cleaning the audio” has.
This is going to shake up (and simplify) my audio editing. I am not going to do all that fine tune editing, and only remove things that are gaffes or just not relevant. This should make me much faster at editing.
And ummm, I am going to reset my own assumption, and um, accept my um, speech pattern is what it is. I think Michael Berman summed it up most eloquently.
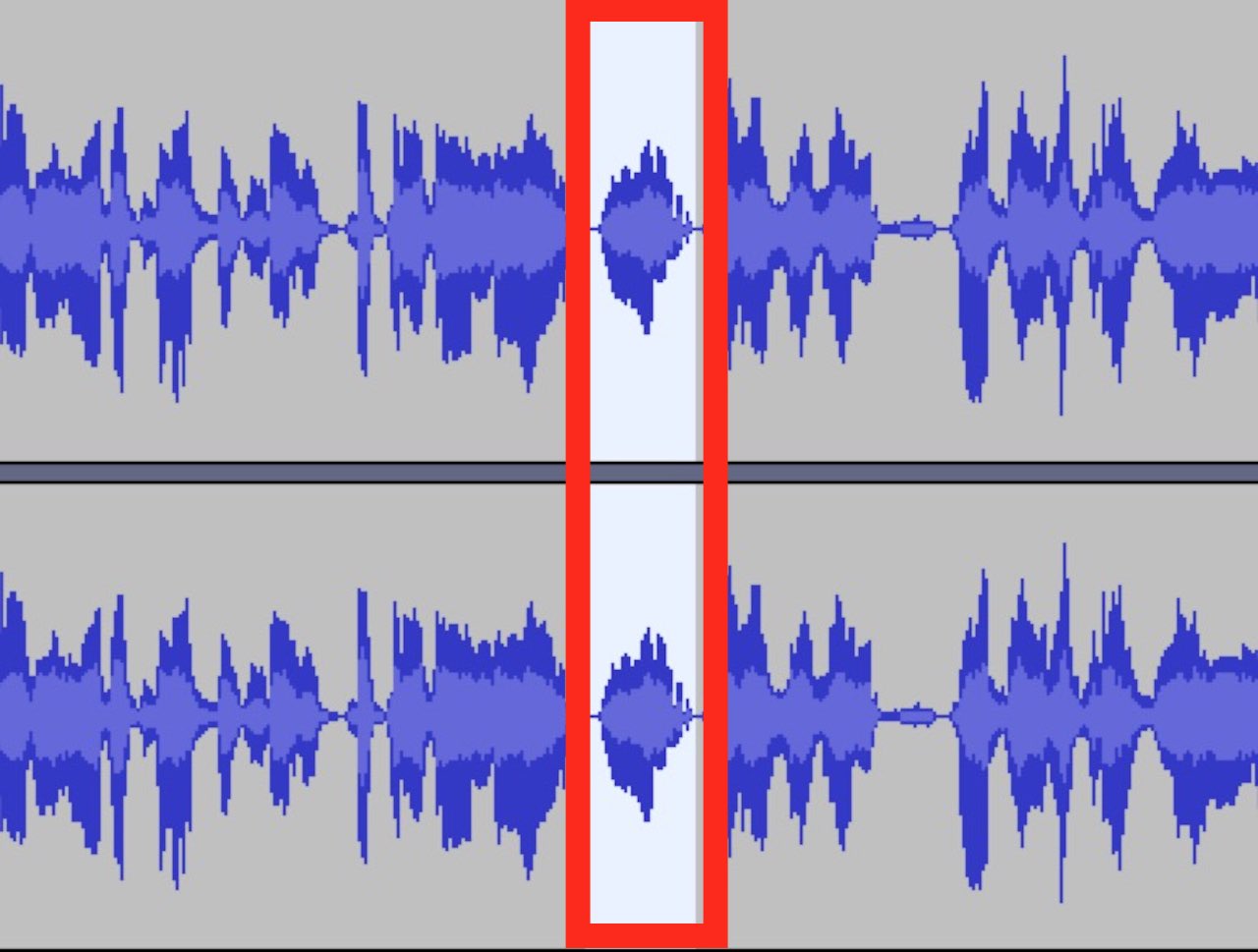
Featured Image: Screenshot of a recent audio editing session, my own voice track with highlighted the tell-tale hump shape of my “ummm” in the waveform (sharing here under a Creative Commons CC-BY 4.0 license)
Hi Alan,
Thanks for this.
One thing I liked when I did Radio Edutalk was by doing the show live I felt no pressure to edit the archives, beyond a bit of levelling and trimming my technical problems at the start of a nicecast broadcast.
One of the values, to me, of listening to a podcast is the extra information, often emotional, that is carried by the voice. This research linked might support that premiss.
As podcasting gets a lot more professional, one of the downsides might be the loss of the unedited voice.
Thank as well, John. And it’s helpful to compare to the experience of live broadcast, and perhaps the only difference is when it is streamed. My podcasts are not really structured, but even setting up the experience as to be a “live” (aka human) session might help. I just need to remind myself.
Alan, I’m glad you’ve decide to accept your ums. My take on this is very similar. The filler sounds happen all the time and are a natural part of speech and generally shouldn’t be removed. Yet microphones and the compression of dynamic range of sounds and considerations for headphone users getting everything stuffed right in their ears still leaves me occasionally removing some filler sounds. In particular the tongue-clicks at the start of sentences that Gardener Campbell mentions – if a guest or host is positioned in relation to the mic such that this sound is emphasized to the point of being louder than I would hear it if in the room with them, I will often back it off or remove it. Especially if it is frequent. Like, frequent enough to trigger a listener’s misophonia. I do the same for the dreaded whistling ess (listen to a John McCain speech for ample examples). With ums, ahs, if there is a bit of a pause around them I may remove them to reduce the pause, or leave them but also reduce the pause just so the listener doesn’t think their player stopped. But if they are frequent enough to start to annoy, I will try to randomly snip some out in a way that preserves the flow of conversation. It’s definitely a dance with sound. I don’t think we hear the filler sounds the same way through mic-recorded, earbud-delivered sound as we do when we are in the room so I try to balance that in my edits. You wouldn’t sound like Alan without an um here or there. ?
Thanks, Cheryl. That’s close to my current strategy, only minimal pruning and noise removal. And there is likely something to support that they way we hear ourselves is not really how others hear us.
My mom’s and ahs are part of me! Don’t edit me!!!!! 🙂
Waving and ummming
Nancy, you get a permanent pass on editing. And you are… perfect.
It’s a well known fact that people retain information 600% better when the um count is between 1-6 UPM (Ums Per Minute). Lower than that, and it doesn’t feel authentic. More than that, and it’s just UMMMMMMM. Which might not be bad, depending.
It’s good to have the facts behind me!
Even if you leave in the umms, you might be interested in this podcast automation conversation. It’s a bit rough to listen to at times but the workflow automation and new options beyond Applescript/Automator are pretty interesting (although maybe just for the newer OS? I can’t recall which one you’re using currently.).