Enough energy has been spent here combing through what Google Image Search excretes for Creative Commons licensed images. So much that it merited a new tag.
And yes, they seem to have twiddled a few knobs the results have ascended from only 3 CC licensed dog images found September 27 to an astounding 114 just now. (I have only 3963 CC licensed photos of dogs in my own flickr account).
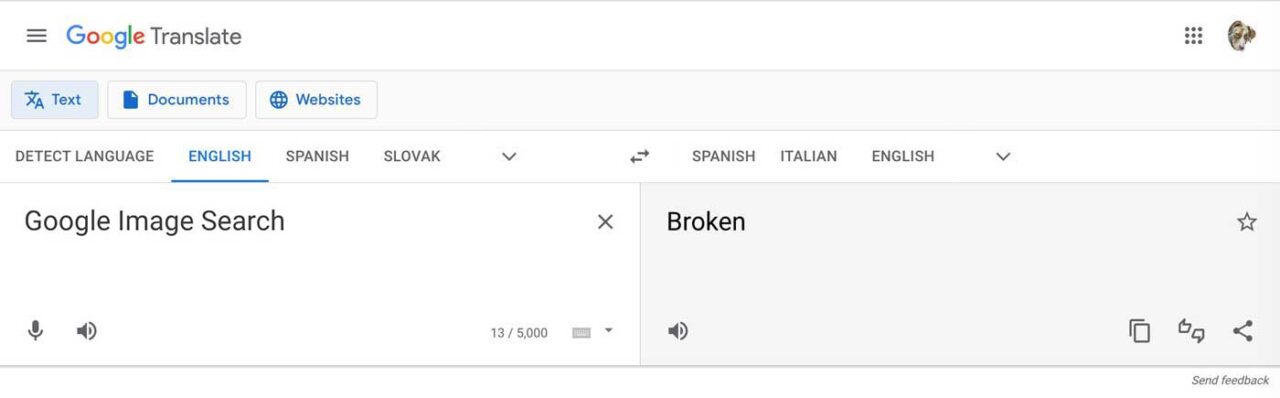
With the aid of Google Translate, the issue is clear
But if you want to cut to the chace, ace, take your searches to Openverse – the successor to Creative Commons’ CC Image Search.
A Wee Bit of History

The original CC search (bless you Creative Commons for leaving an archive) as it’s disclaimer reads, is not a search engine. It offered a single interface for entering a keyword, then handing it off to he searches from several different collections (flickr, google-yeah-images, Wikimedia commons, cc-mixter for audio, etc). And it still works!
I saw early the next generation version of CC Search that was a true multi-site search engine that operated on metadata for some 19 different collections (see news post).
In 2021 CC Search was transferred to be owned/operated/maintained by WordPress where it lives now as Openverse (have you tried it yet?) (heck stop reading my blathering and try it).
While I tried it out and liked the Openverse features and assurance of knowing results were clearly licensed, I found I did not quite zero in on the kinds of images I could (then) get easily from Google. But unless you stuck to reliable sources in the results, I ended up dipping into a slimy pit of public domain leach sources and noting that a raft of such sites were scavenging from other more legitimate sources (flickr, Pixabay).
Then Google Images fell over, lame (blogged, blogged, and blogged).
Who Knows About It?

The most surprising thing in responses was how few people, especially in education, even knew about Openverse.
Here, just check out the ways different organizations provide guides to finding CC licensed images and how few of them mention Openverse (actually I did find some). It’s also something that bothers me that most resource guides become this laundry list of links, and do not provide as much guidance to search strategies… sometimes it seems like an overloaded list of options that would make most people new to this overwhelmed.
And then the name -Openverse, what is that! I get it. It’s a Universe of Open stuff. But sadly it has a similarity to a currently hyped term. But what’s in a name, and it’s already named.
I’m not here to make a call on marketing, but I do not see much promotion or awareness efforts to make Openverse known. Yes, I see some tweets from WordPress, but…
Not that it makes a huge difference, but starting here I plan to not just share it, but to use it extensively myself (heck I did post it December 2021 in the OEG Connect community).
What’s So Hot About it?
Get the pun?

It’s here I try to make a case that it’s not just about getting gobs of results, but that if you are committed to open content, with what you find in Openverse
- all the elements of good practice, TASL or Title, Author, Source, License, are clearly provided
- the license is not ambiguous or hidden (and can be a filter on results)
- it provides cut and paste attribution.
Oh and you can also save your finds to come back to later.- It now lets you search for audio/music
But the biggest thing is that it takes way any uncertainty on the usage of the images. No guessing the license. No being served up media from sites that do not give credit to the author.
What are you waiting for?

For that matter, what am I waiting for writing all this palabra before even getting into the demo.
Jump In

There’s not much to give for direction to get a first taste… go to https://wordpress.org/openverse/ And there, type in a word in the box. Did I really have to explain? But woah, neo, 600 million items, surely you can find something.
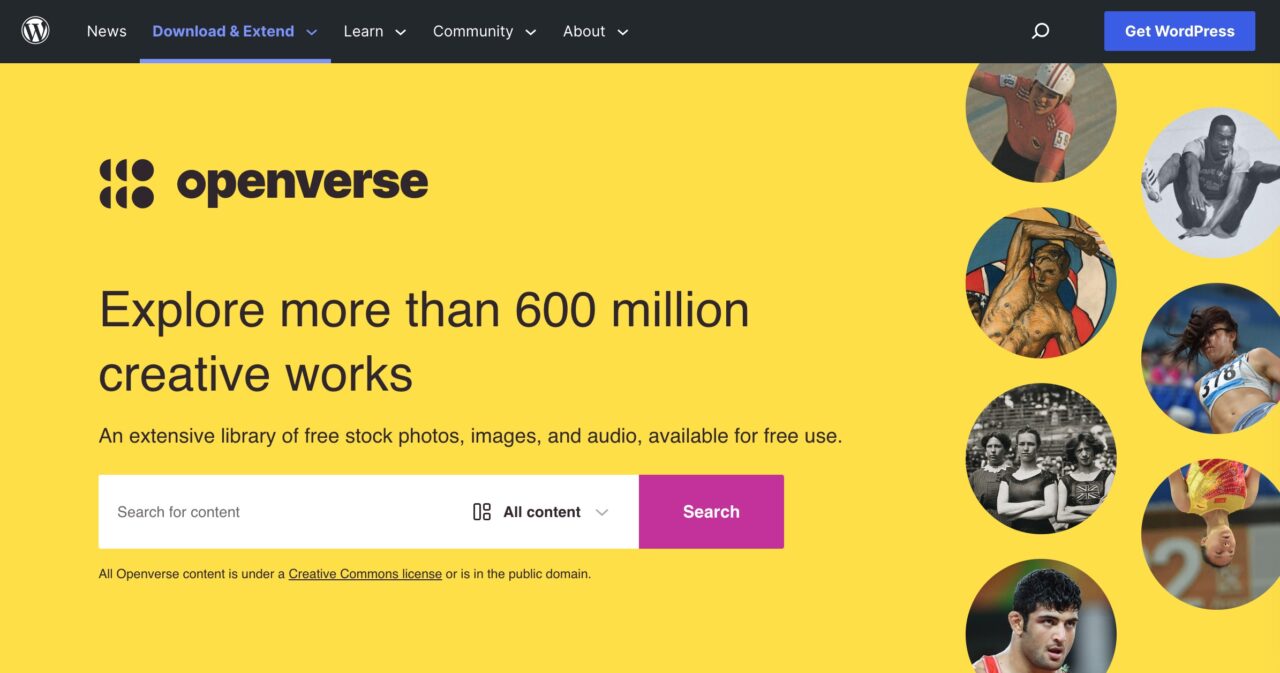
You might guess my test search. More than 10,000 Creative Commons licensed images of dogs. All of them with a definite license (shown in icons on a hover). If it’s just by numbers, well Openverse 24, Google 0.
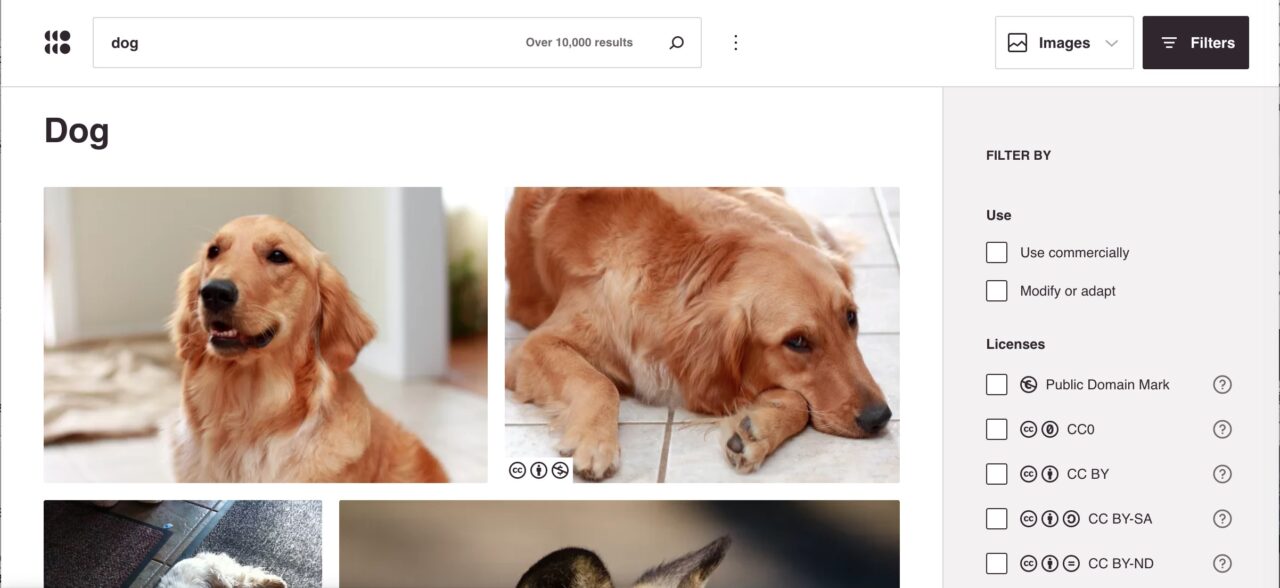
But give those check boxes in right a try. They filter the results in real time, so you can narrow in broadly on usage (commercial or modifiable), and also the licenses you may want to limit to, here to those CC0 or CC BY hounds.
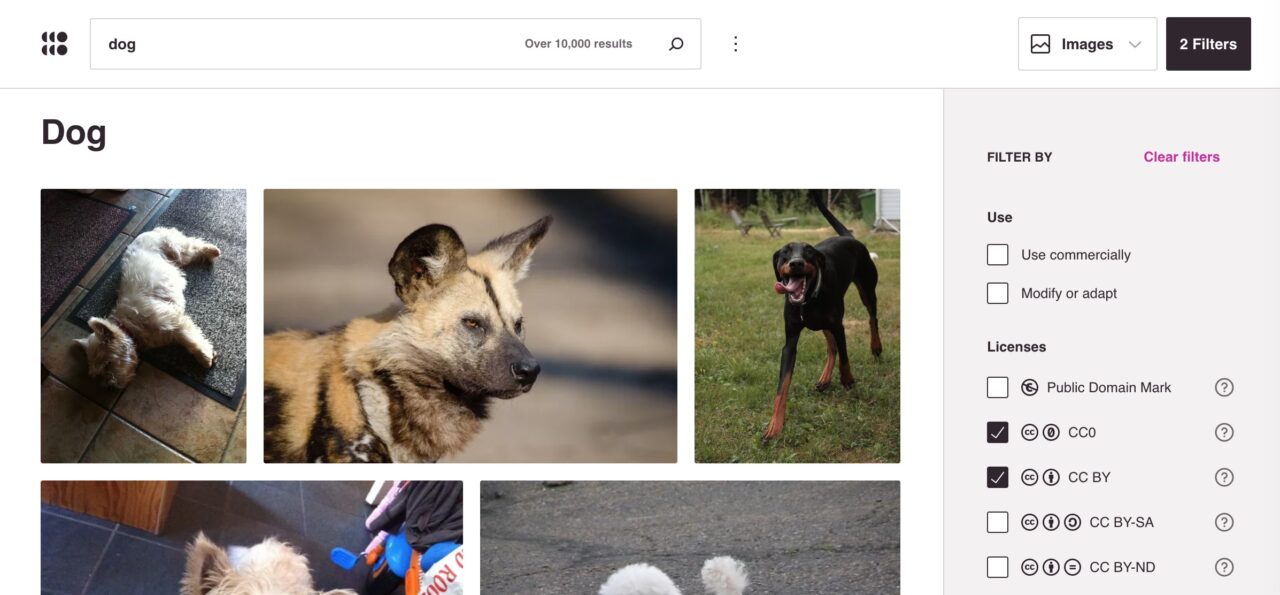
There’s a massive set of filters- type of image (photo, illustration, or digitized art), file type (PNG, JPG, GIF, SVG), aspect ratio (portrait, landscape, square), size (small, medium, large), and source (45 providers from Animal Diversity Web to World Register of Marine Species).
That’s a lot of filters! And you can really fine tune searches like mine for dogs licensed CC0 or CC BY, JPEG format, wide orientation, large sized, and from either Brooklyn Museum, Cleveland Museum of Art, Museums Victoria, NASA, Rijksmuseum, SpaceX, or Wikimedia Commons. (that’s a bit overboard!)
As mentioned earlier, from the results I can hover to display an icon for the license (might be nice to see too the source?).
Let’s see what info we get for this figure of a dog

Below this image is much more useful, accurate information than I get at Google Images.
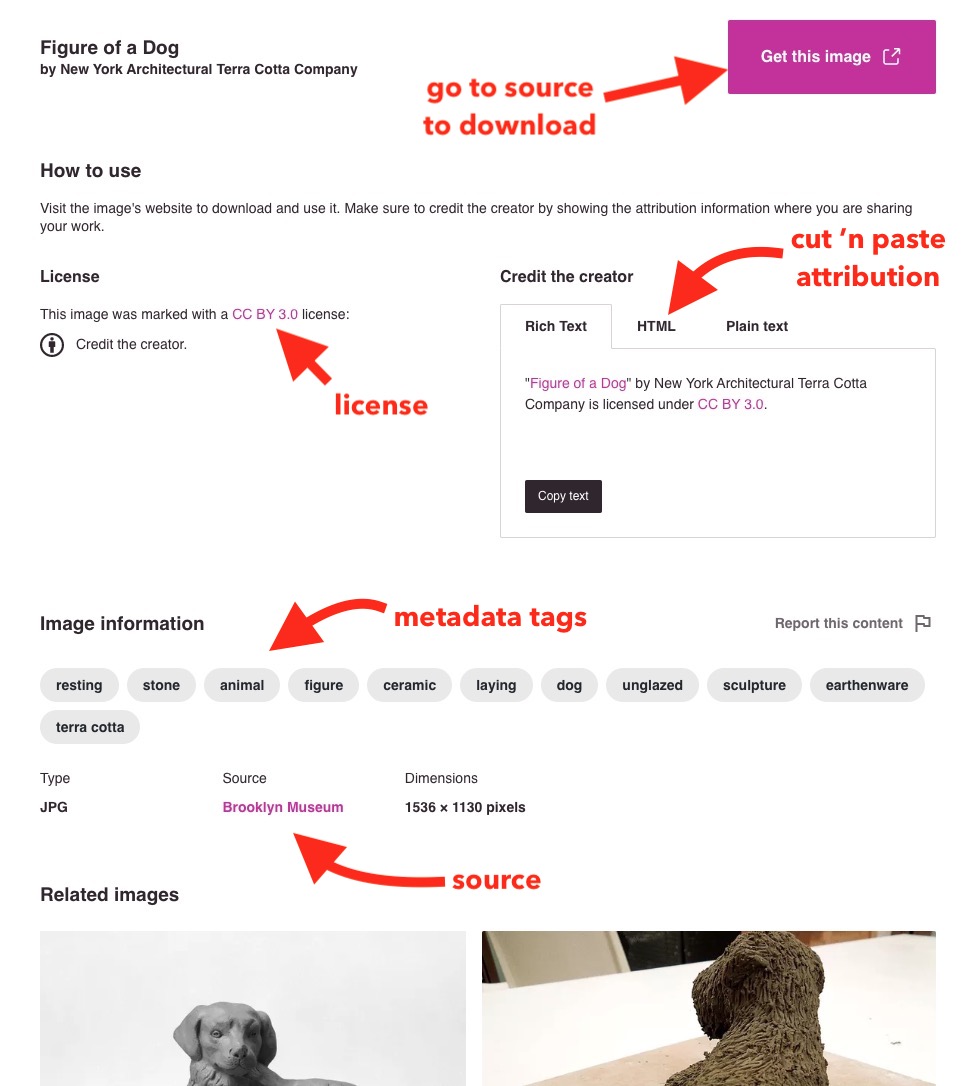
Noting:
- Openverse does not store images beyond the preview, I have to go to the source page for a result and figure out how to download.
- The license is very clear and comes from the metadata of the images record, not dependent on exif data or making guesses from the host page content like Google does (poorly).
- The attribution text is what we can use readily – I copied he rich text one and pasted in above for the images caption– that is super simple
- The tags are from the items metadata, they are indicators of search terms that would find this image. Note that they are not clickable, I cannot click “terra cotta” for a new search
- The source collection is very clear and reliable
- Related images can be helpful (see below)
Openverse Plays Well Inside WordPress
If you use WordPress the joy of dog searching… well any searching, is much higher.

It could not be easier if you use WordPress and have the Jetpack plugin enabled. From the Add image block everything is there:
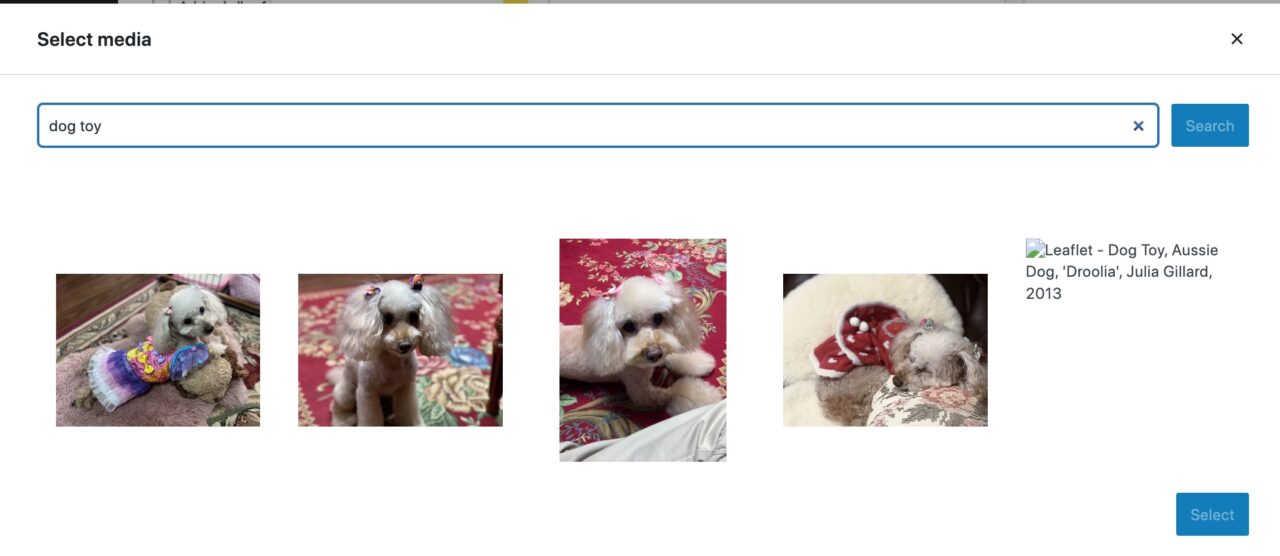
I just searched Openverse inside the WordPress interface for “dog toy” , clicked one from the first row. Them it was inserted into the post with an attribution inserted as a caption. And the image is added to my Media library. It could not be easier.
I did notice some issues here. You get no search filters. I can live with that. You also only get small thumbnail previews, no click through to see larger version or any other photo info. And even more interesting/problematic, the Openverse search results inside WordPress are much more limited than directly from the same search on the Openverse site.
I would guess that is a performance issue (?).M
My Methods are Evolving

Searching is as much art as … well practice. I am finding my keywords choices I might use in Google are not working as well here.
I wondered too about keyword order, as I found different results for a search on “bird prey” than for “prey bird” but after posting in the Openverse Slack I got insight (I forgot myself that order has a difference in Google too). Olga from Automattic answered this (and several others)
Yes, this is expected. The search result is boosted if the text contains the exact phrase match. So, “Prey bird in Pacaya y Samiria…ID ? (forgoten)“) is higher in the results than “birds of prey, birds of prey flying HIGH in the SUMMER SKY” . This is true for other search engines, too, I believe (I only checked Google images). On a related note, if you search for the same thing in a different language, you will also get a different result, even though images have no language. And that is also the same for other search engines.
I will make use in my searching of a bookmarklet tool I built out of clay (just kidding Javascript)
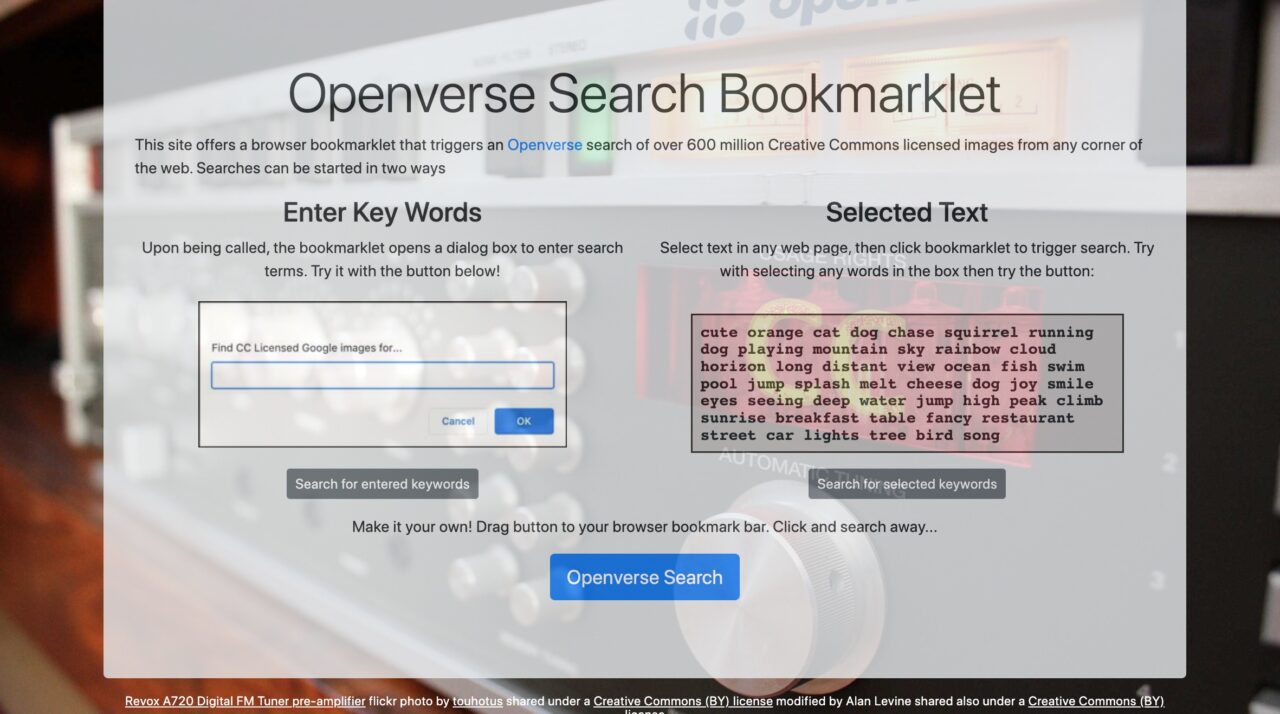
This means I can initiate a search without having to click over to Openverse- clicking the bookmark provides a keyword entry dialog box. But even more slick, I can highlight a word or more on any page and trigger a search based on that. It’s the image search bees knees.
Curiosities and Notes
- I was not too sure how Openverse sorts/orders its results (of course Google never tells). A response I got in Slack was “The current sorting algorithm is based on the metadata that the users upload with the image when sharing it (title, description, username, tags). We match the search text to the text in those texts in descriptions. For sorting, we also use the popularity data from the sources (like the number of views on Flickr), which might result in older items being higher in the results simply because they have been up longer and have been viewed more times. We also boost the ‘Authority’ sources like museums or curated collections.” I have noticed that flickr images Openverse delivers do generally have a high view count.
- Almost every search returns predominantly results from flickr. I would guess this is because here are so darn many CC images in flickr, a good thing indeed (heck, 69,000+ are mine). I’d like to see more of a mix, or variety. Of course, I could manage or tweak this with the filter settings.
- Related Images are close to home. I was curious about the value of related images, but in most of my tests (like 10) the related images are all ones from the same creator as the result image. That seems to be limited.
- Music/Audio Search is so valuable.
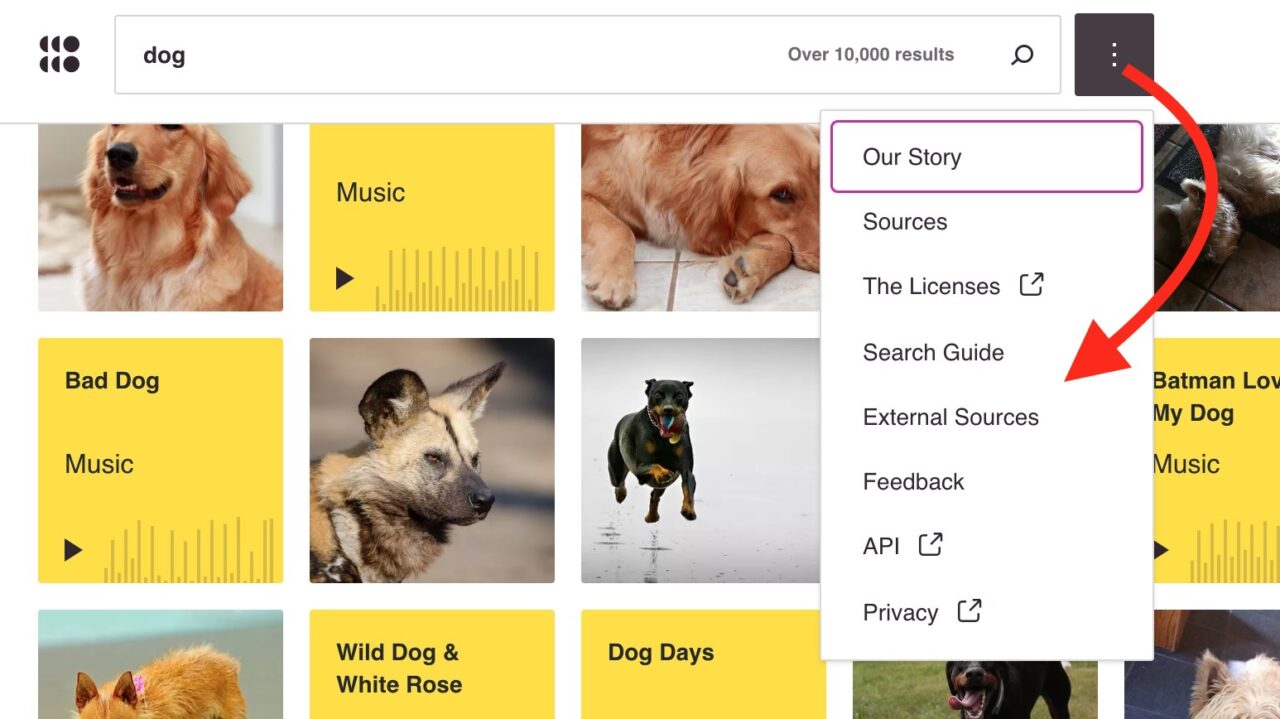
- Site Information hard to find. It’s not too easy to locate information about Openverse. It’s iframed inside of a generic WordPress.org menu, which does not offer any navigation for Openverse. I finally found it hidden inside a 3 dot menu next to the search field. And thus I accidentally found some key information for syntax in searches like quotes around a phrase, negation, and/or, patterns. Heck I can now apply Levenshtein Edit Distance !
- I‘m a tad partial to my attributor. Maybe biased because I built and have used my Flickr CC Attribution Helper that goes back to 2009. But Openverse absolutely covers the full TASL.
- Missing Things. The original CC version had both a Chrome Extension available and a feature to create a collection of finds. These are gone but maybe are just in the shop being worked on.
Me ‘n Openverse

This is the start of a great relationship! I get the sense that there is still a lot of work on the inside getting the collection data harmonized and fine tuning the performance.
There’s hardly any support information there for users,though it’s pretty intuitive how to search. Heck even a cat can do it.
If I was working to onboard, train people new to using open content, I would start them with Openverse rather than giving the laundry list of other sites that have different license flavors than CC. The license and reuse requirements are made so clear at Openverse. Then with experience, I might let folks branch more out as their search, reuse, and attribution skills are established.
I definitely would steer new folks away from Google Images.
Let me know what you find from trying and exploring Openverse.
Featured Image:


AmFingAmazing!
Will definitely be searching for images on OpenVerse every chance I get. Google just lacks the will and commitment to being good at this nowadays. Like so many other services/api’s/betas it’s just on some kind of long-tail maintenance mode, until they decide to destroy it.
Whoa! This is pretty detailed so thank you for explaining it all. I had seen ‘Openverse’ in one of the selections for Image upload in WordPress but didn’t explore it. Instead, whacked a search term in there, to see what it came up with but I hadn’t explored the rest of the site. Thank you so much for this! Definitely my posts will go up a notch.