A typical scroll trip through almost any social media stream. People share a link to something from the New York Times. Clunk. Another from the Washington Post. Thud. MIT Technology Review? Splat. Almost anything resembing a newspaper? Clank.
Sure you might get one free read a month, but with every annoying frequency, reading most sources of news are asking for $ or subscriptions, even just asking for email is something you are paying for with your info. And if no wall, once you try to read, it’s a trap field of closing popups, jumping over ads.
Is this really the web that was a dream? How did the Mesh become a Mess? That’s for another day, and I don’t see any sign that someone buys my theory.
For while for New York Times articles I used a trick that if you could pull up a link in Google Search, it let you read a full walled NYT article. I’d copy a headline, search for it, and click in through the wall. I even hacked a JavaScript Wall Jumper bookmarklet. But that method vanished.
Jump the Wall With archive.today
Okay, back to the topic. I was looking a few weeks ago for the story of the first URL shortener. Indeed Wired has a post from March 2004 that shows up in search result, and as you get below the fold…. CLUNK.
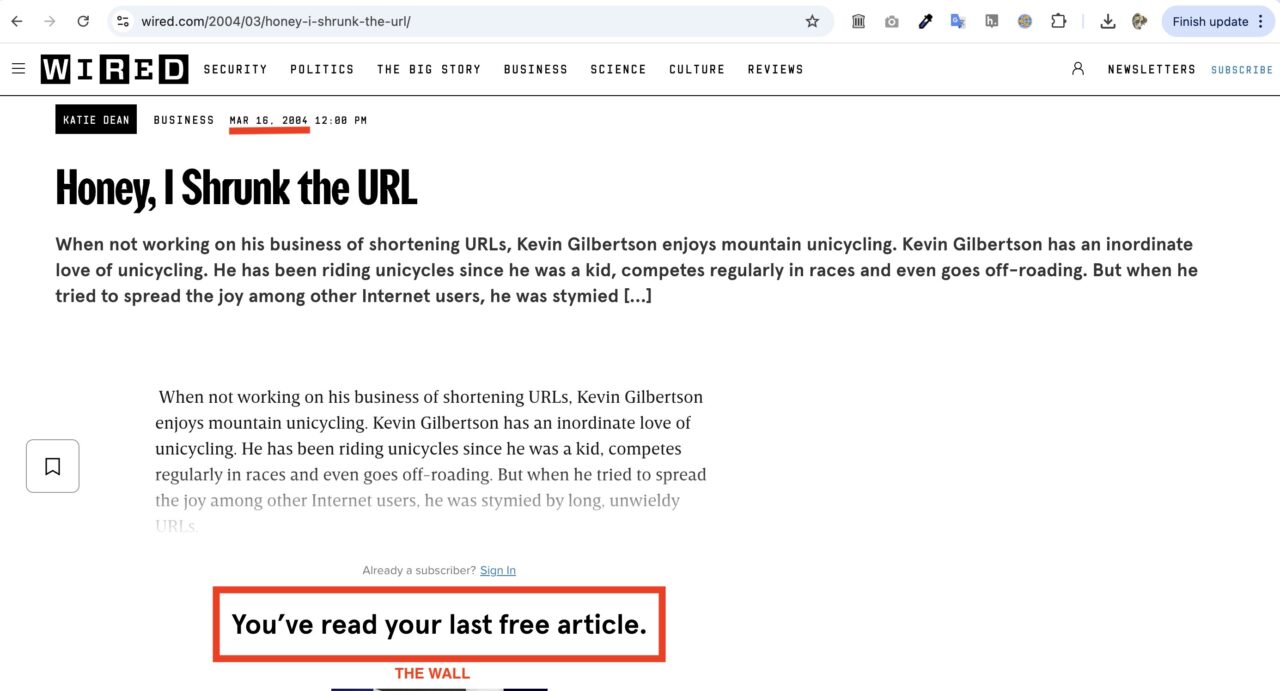
I give you the keys around almost all pay / subscribe walls. Warning, it involves actually manually editing a URL in your browser. I know this is a serious technical obstacle. Just go slowely.
So right in your browser, where the address reads https://www.wired.com/2004/03/honey-i-shrunk-the-url/ stick right in front of it archive.ph/ making the full link http://archive.ph/https://www.wired.com/2004/03/honey-i-shrunk-the-url/
Press RETURN.
You land at a site called Archive Today. If this link has been archived already, you will see it below the box (often there are many snapshots).
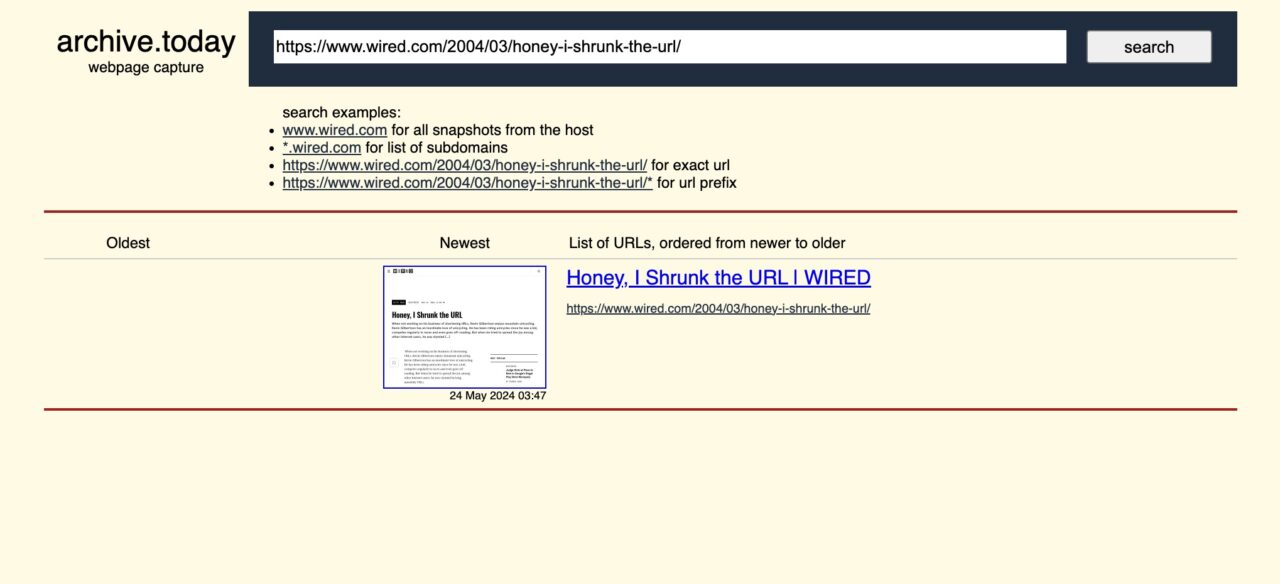
http://archive.today/SP9s5And BOOM, you can read the full article. Without ads. Without popups.
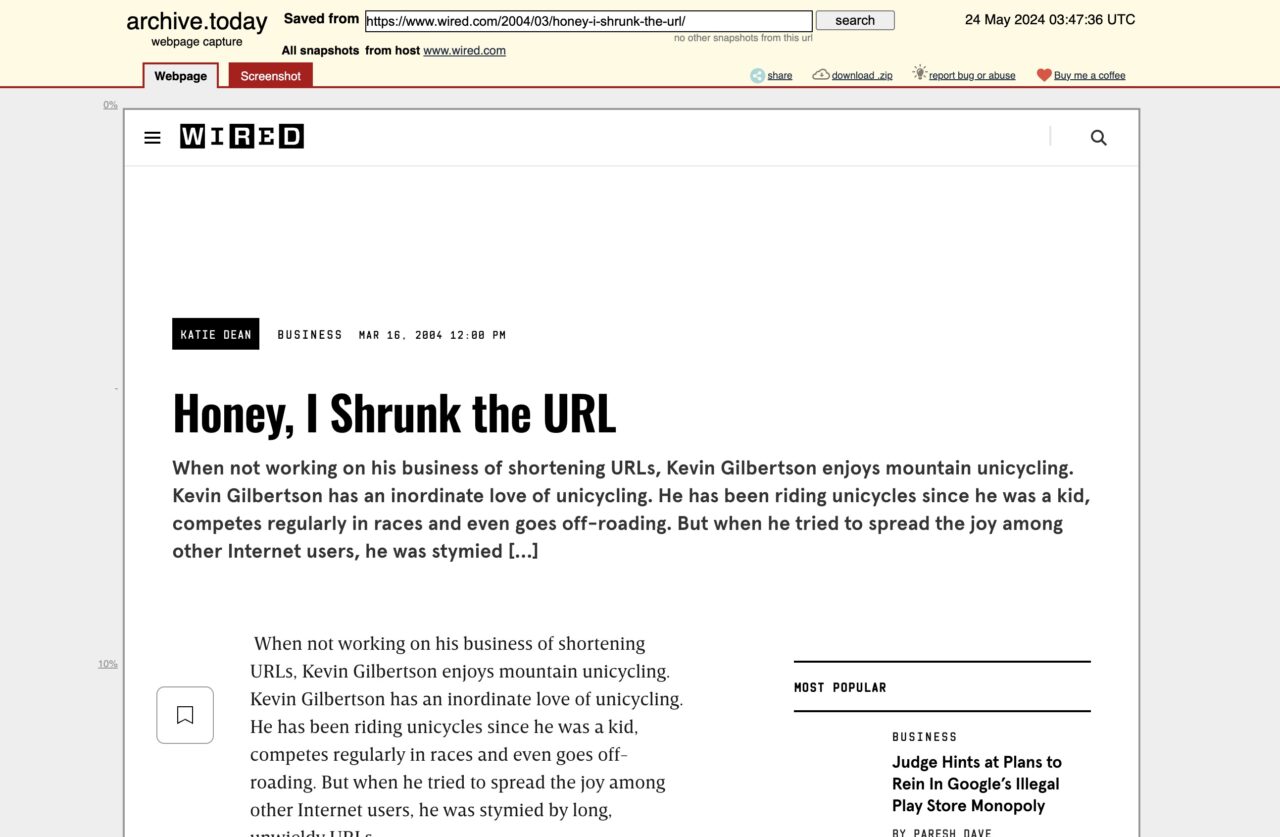
It’s a few steps, but… it feels so liberating. Like jumping over a wall in a single leap, landing in a field of flowers.
I have been using this regularly for, well so long I forget. I share this as a gift for your own reading practice, don’t be walled in.
Make Yourself an Agreement – Never share a Paywall Link?
But also.. and this is a big ask, when you share stories from walled sources, please share the archive.today link. Make it easier for someone else to glide right over that wall. It’s a matter of when reading the article like above, click the share tab, where you can easily copy the sharable link, e..g. http://archive.today/SP9s5
It’s my practice now. Sometimes when I see in Mastodon or elsewhere (I don’t do all the other spaces anymore), I sometimes reply with the archive.today link. I keep thinking people might pick up the practice. And when I have suggested to some colleagues that do lots of link sharing, I get some feedback like “that’s too much effort” or “I hope ny audience knows how to do it themselves”
Horse poop.
What a Minute! Is that an Archive? Is it Kosher?
The names get confusing. The service is archive.today I find the trigger to make a clear link is via archive.ph and sometimes you see links via archive.is Confusing? Only until you do it a few times.
Also confusing- this has nothing to do with the Internet Archive.
But you should be asking yourself, I did right way, how the bleep is this even allowed? Is it illegal? Wouldn’t the wall makers be taking it down? Well heck yes, its on the edges, and certainly it is not something I would consider an “archive”, it could easily vanish.
There was service for a while called 12ft.io that did the same thing. Indeed the News / Media Alliance (which sounds impressive but its a bunch of publishers clinging to power) took it down.
What is its story? It’s got to be illegal. I was even worried that my vast reach (hah) might give more notice.
It’s rather odd, as everybody keeps whinging about how bad web search is, and I got an answer in 10 seconds 4 links down, no AI summary from a post by Jani Patokallio on a site called Gyrovague “archive.today: On the trail of the mysterious guerrilla archivist of the Internet” and the site goes back to 2012. All in all, it is not even clear who is behind it:
While we may not have a face and a name, at this point we have a pretty good idea of how the site is run: it’s a one-person labor of love, operated by a Russian of considerable talent and access to Europe.
https://gyrovague.com/2023/08/05/archive-today-on-the-trail-of-the-mysterious-guerrilla-archivist-of-the-internet/
It is supported by a mix of some ads, donations, and some mystery flows of money, and is apparently not cheap. My guess is they pay the wall fees so their scripts can grab the articles.
The less discussed but more controversial half of the site is scraping, the process of vacuuming up live webpages. Since 2021, this uses a modified version of the Chrome browser, and the blog readily admits that the availability of computing power to run these automated browsers is now the main bottleneck to expanding the site. To avoid detection, archive.today runs via a botnet that cycles through countless IP addresses, making it quite difficult for grumpy webmasters to stop their sites getting scraped. Access to paywalled sites is through logins secured via unclear means, which need to be replenished constantly: here’s the creator asking for Instagram credentials.
https://gyrovague.com/2023/08/05/archive-today-on-the-trail-of-the-mysterious-guerrilla-archivist-of-the-internet/
So one person is running a shadowy operation that has escaped the tendrils of the Mighty News / Media Alliance. The mystery person writes “Of course, it is doomed to die at any moment (you should not have any illusions, as well as about the “veracity of content” on the Internet). The only idea is to hold back a little something that is doomed to die a little earlier.”
It likely will not last, but I am cheering for it to go on. It’s a mighty rebellious effort of that guy with a slingshot bringing down the monsters. So for now, I will use it regularly to read the web they way it was supposed to work. Not this clusterblarg of barriers and traps and enshittified barnacle coverage wrapped around information.
Arm yourself with archive.today or just stare out blankly at the paywalls. Me, I’ll take as many leaps as I can, I will extend a lift to as many readers as I can.
Jump the walls. Tell someone else.
Featured Image: 2016/366/33 Over the Wall… flickr photo by cogdogblog shared under a Creative Commons (BY 2.0) license


@barking Jump paywalls while you can with archive.today
Fantastic story looking for the mystery person behind it all
https://gyrovague.com/2023/08/05/archive-today-on-the-trail-of-the-mysterious-guerrilla-archivist-of-the-internet/
Remote Reply
Original Comment URL
Your Profile
Why do I need to enter my profile?
This site is part of the ⁂ open social web, a network of interconnected social platforms (like Mastodon, Pixelfed, Friendica, and others). Unlike centralized social media, your account lives on a platform of your choice, and you can interact with people across different platforms.
By entering your profile, we can send you to your account where you can complete this action.
Full credit to CogDogBlog for first mentioning this on Mastodon. I too was on the receiving end of one of those entreaties, nay criticisms to do everyone a favor and “use the archive.ph trick”. And like most I was slow to understand and appreciate. But I would say in the most recent (and boy do I mean recent, let’s say last two weeks) have been using archive.ph on numerous shared links in my “toots” on the instance where I reside. So kudos to CogDogBlog! He knows that of which he speaks and just DO IT!! It’s magical, just pre-pend https://archive.ph to the front of any/all URLs and get the shortened url off the page that results from that simple act of manually altering the URL in the URL bar on your browser. IT Friggin’ works! It’s beautiful.
Thank you for the hack — I had pretty much stopped sharing URLs because of all the barbed wire fences.
Thank you. I will try it. Those paywalls are so annoying!