At a session today on “Deep Learning” at the ASCUE17 conference Steve Kenode lauded the merits of advanced machine learning, like Deep Mind‘s “learning” the best way to play Breakout
I did appreciate the schematic way he explained it for a lay audience (including me) with the way weights are assigned to relationships; I’m a bit bothered by the terminology of “hidden algorithms” but that’s not my thing to take on today.
Steve raved about the ability of Google Photos to automatically access your photos and do “amazing things” to organize them (“you don’t need to write captions”).
I like writing captions on my photos.
That’s not the point either.
I was intrigued by the demo and the site for Clarifai a photo and video API that provides (tagline) “Artificial Intelligence with a Vision”

Don’t get me wrong, it it’s mind boggling to see how just an analysis (hidden) of an image can identity or suggest often very accurate descriptors and recognize faces.
Like pizza, when it’s good it’s really good.
And since they offer a demo, I gave it a spin to see if I could give it a good challenge.
So I first sent it a photo I did this winter of some of my toys playing on a table with some snow. Here is the original

2016/366/335 No Peace, No Pipeline, Not Toying Around flickr photo by cogdogblog shared into the public domain using Creative Commons Public Domain Dedication (CC0)
I uploaded an image to the Clarifai demo from a copy I have in my random desktop images folder.
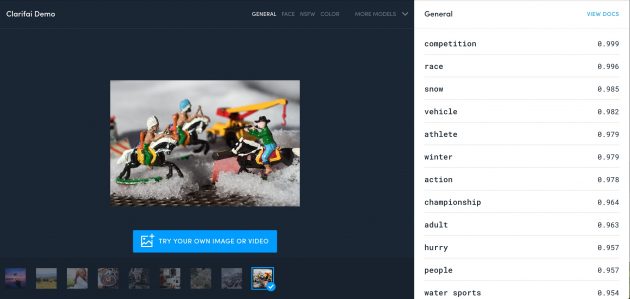
What can Clarifai clarify?
Here are the “keywords” it suggested, along with a “probability”
competition 0.999 race 0.996 snow 0.985 vehicle 0.982 athlete 0.979 winter 0.979 action 0.978 championship 0.964 adult 0.963 hurry 0.957 people 0.957 water sports 0.954 festival 0.951 motion 0.942 fun 0.934 wear 0.911 fast 0.905 sports equipment 0.901 veil 0.896 exhilaration 0.893
I have to say maybe snow, winter, people, or vehicle are fairly good guesses.
There’s a lot that are fails.
Here is another one, a very large anchor chain, maybe this was taken in the Baltimore Inner Harbor:

Linked flickr photo by cogdogblog shared under a Creative Commons (BY) license
Let’s give it to Clarifai…

no person 0.983 one 0.942 people 0.931 flame 0.901 food 0.859 adult 0.818 still life 0.813 industry 0.803 indoors 0.786 wood 0.780 iron 0.760 color 0.754 art 0.750 desktop 0.735 technology 0.733 invertebrate 0.703 hot 0.696 recreation 0.695 energy 0.693 chain 0.687
High confidence are both no person and people? and WTF desktop, hot, invertebrate?
The lowest rated is chain. Hah.
Of course the explanation is that with iteration and/or correction, it will improve.
I don’t deny that.
It’s just that the same thing can be amazing when it works and ridiculous when it fails.
And as “artificial” the subject cares not.
The technology is neat, and there is a free level to play with the API. Someday I may have that need.
But damnit, I am writing my own captions!
Featured Image: Public domain image from pixabay
