Oi, I have many a blog draft bouncing in the brain to recap last week’s outstanding Reclaim Open Conference– if you missed out pretty much of the activity and sessions is sitting there openly for you to rewild your ideas.
Ideally I would have had this post done prior to my Small Piecers Still Loosely Joined session (itself one of saif draft blog posts), but really, who cares about chronologic oder anyhow. I thought of this while listening to the Thursday session on Replacing a live site with a high-fidelity web archive mirror— I was listening while driving so missed the screen postions, but am keen to look at the web archiving capabilities of Archive Webpage using webrecorder.
I’ve had some runs at archiving my own sites in my Web Bones space of this domain. Some of the buried bones are domains I owned but let go, others are from external web services that have gone belly up where I have beem able to grab copies of exports. I was thinking that this approach is pretty much post mortem, saving the web bits before they vanish wholesale.
But another approach that I have found useful are practices that are doing some of the work while you are still using them. A key example has long before He Who Shall Remain Not Named vanquished the platform I will only call Twitter, I was luck to put into play an archive of my tweets that was updated while the platform was one Iw as actively using.
All the credit for this goes to the genius of Martin Hawksey who in 2013 conjured a means to start with an export of all twitter activity to date, and some clever scripting that added to it continuously as I went.
And so I have my own archive built as time went by at https://tweets.cogdogblog.com. The yearly histograms on the right from 2007 – 2023 tell their own story, and all my own tweets are there, reachable by a keyword search. And the death date of twitter being June 13, 2023 being the last time Martins scripts could talk to the big bird by its API, until it was severed by the Evil Overlord.
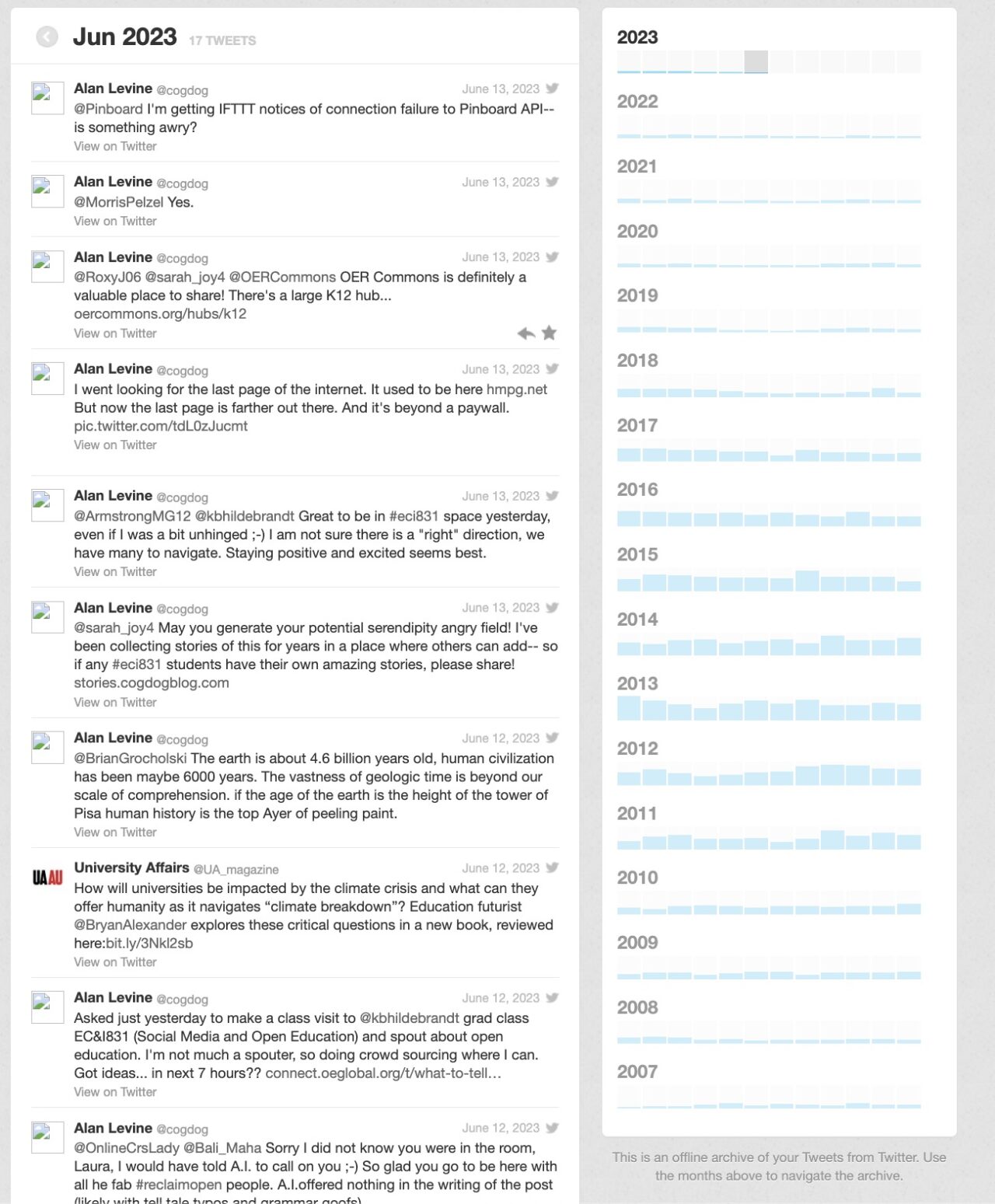
None of the View on twitter links work, alas, as I flushed the whole shebang in January of this year.
But this idea of archiving as I went stayed with me. A slightly different variant is my relationship with flickr, where I have 74000+ photos, with titles, captions, tags posted since 2004. Technnically I know there are ways of archving this, but I am frankly less interested in having an archive of flickr as a copy to hoist somewhere. What I have done is actually for the bulk of this time, used a strategy of writing all of my titles, captions, tags in my home photo managing software (originally Aperture, now Lightroom). This strategy means I am not trusting my “archive” to flickr, but maintaining my own.
Sure you can say this is realy archiving, but I feel confident that since I have all the photo data locally managed, I wont lose it should flickr ever bite the dust.
But back to what I hoped I had slid into my Small Piecers Still Loosely Joined session – that with an understanding of data flows from RSS feeds, slipping them into integrator services like IFTTT and more new favorite, Make.com that I have a number of archiving as I got machinery in place. I quickly overview one of these in the presentation, but wanted to outline them in more detail in Ye Olde Blog Post Methode.
Archiving My Mastodon Activity As I Go
I found I have gotten these mixed up a few times, but the first one I set into motion was via IFTTT from an existing applet Save Mastodon Posts to GoogleSheet by darkillumine – it pretty much gives the steps for how to get your Mastodon RSS feed, and its a matter of connecting it to a Google Sheet that it will append all new activity in the format of date, url, post text.
To skip my mumbo jumbo, here is a peek at my ongoing Mastodon archive, it just runs by itself.
With IFTTT adding to Google Sheets, you can make columns of any fields the RSS feed returns, it’s as simple as it could be.
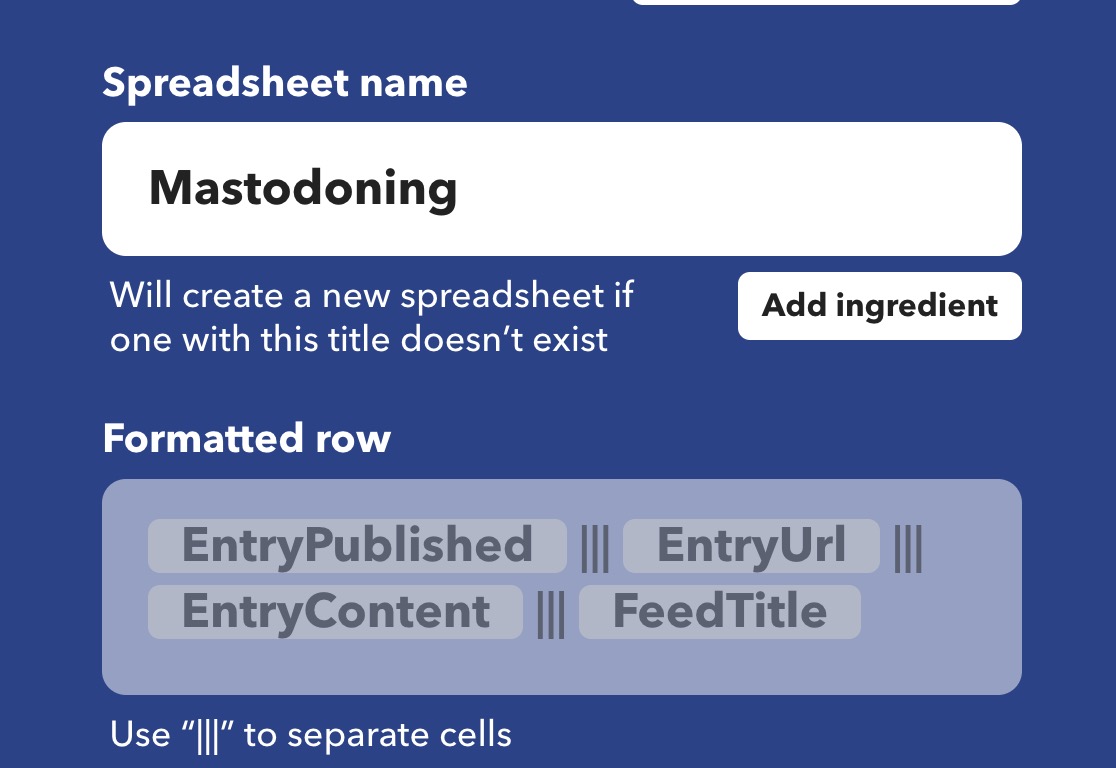
IFTTT shows I started archiving January 19, 2024 and it is matched in my spreadsheet archive, from that date until posts I made today at the bottom (I have some extra functions in place to remove HTML from the post to make it more readable). The archive even spans January 23 when I migrated my Mastodon account from social.fossdle.org to cosocial.ca (I just needed to update my RSS feed in IFTTT)
All fine if I am just archving to keep as a box in my archives. The real reason I do this is I find it more efficient to search here than to try and find in the mastodon search- plus I can search my archive across my activity in different instances.
It both archives as I go but also provides me a search tool.
The task to do now is maybe find a way to backfill my archives.
Up it a Notch: Archving All my DS106 Daily Create Responses
Once you have that basic RSS trigger and integrator action, the world is your archiving peach. And just to show it is not just one tool, this next leap uses Make.com instead. Let’s start the demo with the archive first, go check it out.
So knowing I can get a URL that references all my Mastodon Posts tagged with a #dailycreate in them (cough must remember to include the tag) https://cosocial.ca/@cogdog/tagged/dailycreate the RSS feed is available just by tacking on a .rss to that URL
One thing I prefer about Make.com is it offers broader access to content in the RSS feed and provides the means that I can apply various functions to the result to have them saved in a better format. The columns I am archiving include:
- Date
- Post URL
- Post Content
- Media URL
- Media Description (alt text)
- Tags
The functions built into Make take care of the extra steps in my other sheet to strip out HTML, plus I am able to do some things like take a data array of categories (hashtags from Mastodon) and display them as a strong of hash tags.
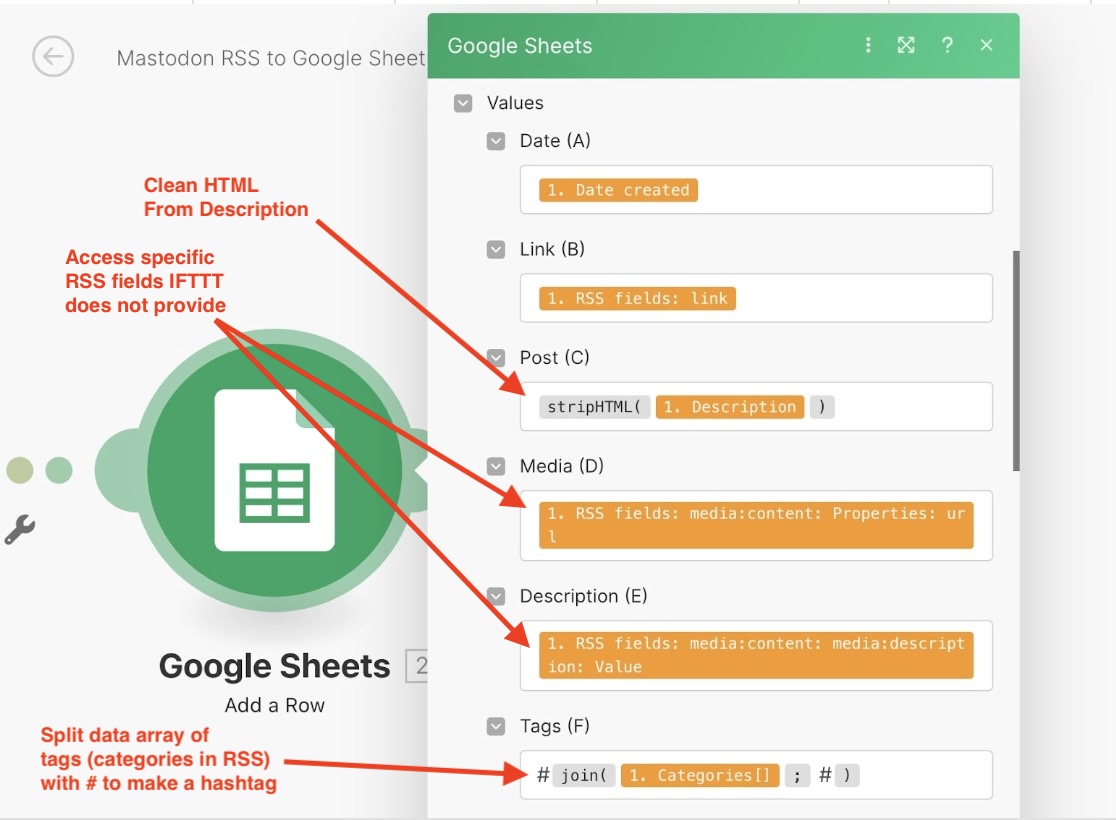
In writing this up I notice my tag sloppiness in that I forgot to add a #dailycreate hashtag to many replies. Oh well, I can at least in Mastodon edit my own posts! What a feature. I might have to experiment on how to pull in the items from the past.
A Self Updating DS106 Daily Create Archive
I got this idea as well to create a full archive back to January 8, 2012 for the DS106 Daily Create, in support of another Reclaim Open session I was part of, the Blogathan lunch break on day 1 Remix is #4Life: Why we All Love the Daily Create and You Should Too – hey that’s another post to write!
This idea came to me that it would be worth doing, especially since the original Daily Create Site is offline; the current site started in September 2015. I saw it as very simple, a 3 column spreadsheet with date, title, and URL to see the full Daily Create (the titles on the newer site all include the Daily Create number as a hashtag).
As we do, here is the final archive, which has been self updating for the last 8 days.
This archive building was a 3 step process:
- Get an export from the database of the original Daily Create Site
- Export all posts from the current site
- Create a gizmo to update the spreadsheet automatically
For the original site, fortunately I know the Man with the keys to the server and Jim Groom was kind in sending my a login to the phpMyAdmin interface that holds all the databases for the ds106.us fleet of sites. While tdc.ds106.us is offline, the database is sitting there.
In dusting oiff my MySQWL chops I knew the info is in the posts table, and was able to get the info needed in this query:
SELECT post_date, post_title, post_name
FROM `wp_5_posts`
WHERE `post_status` LIKE 'publish'
AND `post_type` LIKE 'post'
ORDER BY post_dateThis got a maximum of 500 rows which I could export as .csv and I brute forced ran the query in two more segments to get the data files for all 1335 posts. It still took some spreadsheet gymnastics as the post_name was just the URL slug like tdc32 which I ended up doing some formula work to generate a full URL that is called from the wayback machine. There was some funky named posts, so a bit of cleanup work was needed, as rendered in a google sheet for the original Daily Create Site.
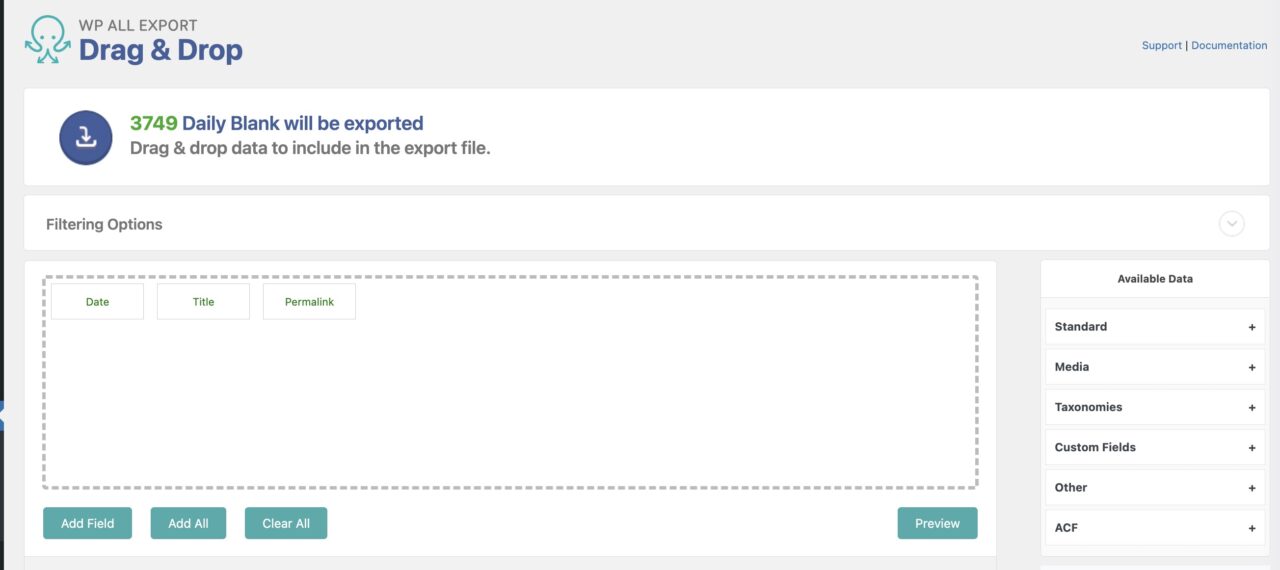
Getting a data export for the current site was easy with a WordPress plugin I have used elsewhere, WP All Export – Simple & Powerful XML / CSV Export Plugin where you can export just the data you need from any WordPress post type. All possible field items are on the right, I only needed for posts Data, Title, and Permalink.
And the ongoing archiving is done with one of those Make.com gizmos using as a trigger, the Daily Create RSS feed. The one trick here was parsing out the publication date as the format in the RSS feed is not how I was listing in the sheet, and was also not a format I could parse as a date format. The easiest way I could do this was by getting a substring of the pubDate e.g. “Sat, 01 Nov 2025 05:00:00 +0000” using substr({pubDate" 5, 11) to get in this case 01 Nov 2025". When added to the sheet as a date, the format of the column displays as YYYY-MM-DD matching previous entries.
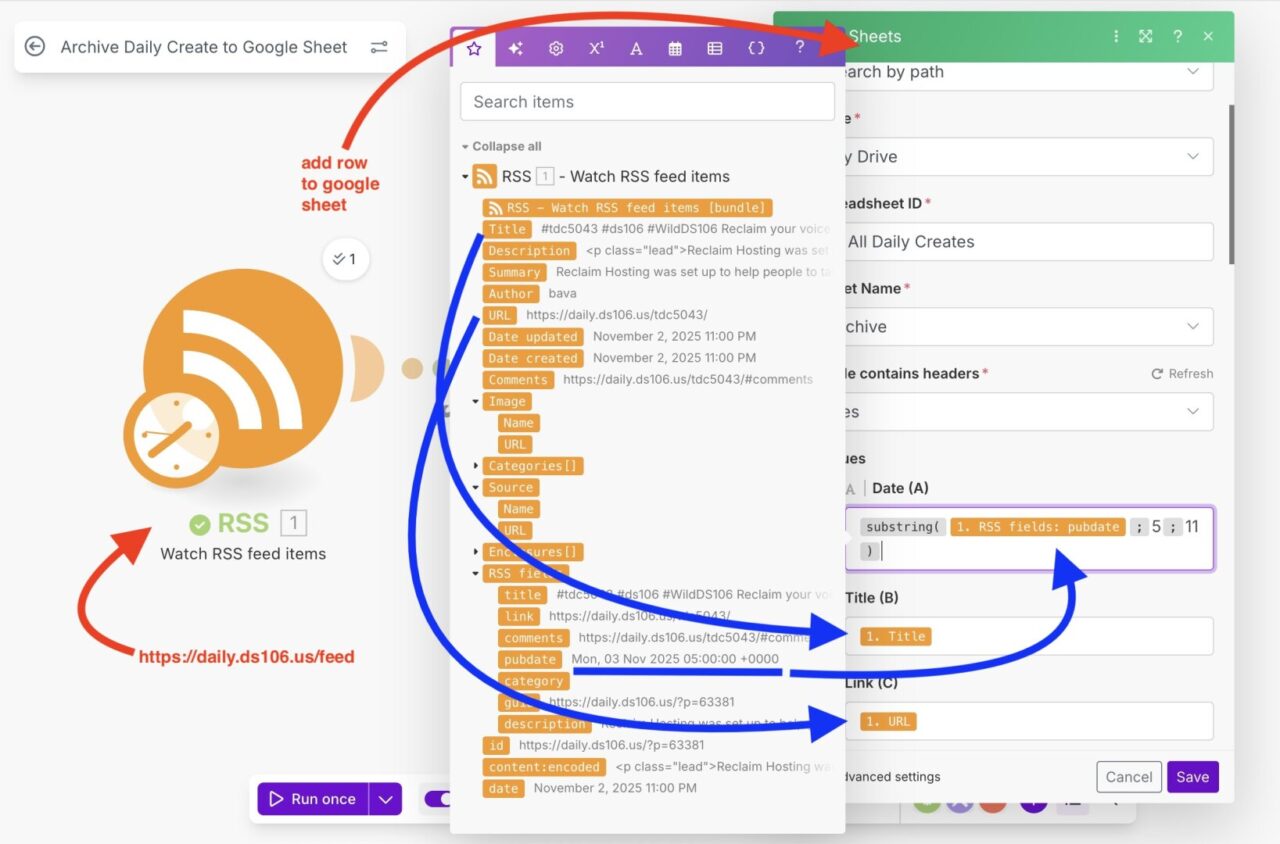
The final spreadsheet collects the newest Daily Create at the bottom of the archive data, I added a second sheet which reverse sorts it to show the newest ones first.
Not Sure This is Everyone’s Cup of Joe
That’s a lot of detail there and I am unsure if I can explain how interesting I find this tinkering. Thinking it through has been a helpful exercises as I had not considered before this practice of Archiving as you go, which in the end, may save you the trouble if having to archive when a service shuts down.
But more than that, I do it when it also serves my own purposes/needs, e.g. for a better means to find my own past Mastodon posts.
I am also for sure to scratching the surface of what Make.com can do, to me it is an order of magnitude more useful and powerful than IFTTT (and I can see I need to migrate more of my gizmos from there so I can nuke that account).
Archive as you go, weeeeeeeeee.
Featured Image: Public domain image from pxhere CC0

