I should not be amazed anymore where a single link click will lead me. But I remain, happily amazed.
While it may only be marginally related to my new Creative Commons Certification project, some thinking about how reputation works in online spaces seems relevant. If (big impossible if IMHO) reputation can be measured, it can be used in terms of analyzing influence and status from the networks we inhabit.
As the serendipity things goes when you toss a blog post out into the open spaces, my journey was kicked off by a tweet from Chris Collins (aka “Fleep Toque” who I got to know like 7 years ago in Second Life).
"Seeking Evidence of Badge Evidence" https://t.co/BOOB9D4AAt Reminded me of "reputation economy" https://t.co/Vpt1kKW4cD @cogdog @dlnorman
— Chris M. Collins (@fleep) March 16, 2016
Before I write about Fleep’s post, a side path was opened by D’Arcy Norman, triggered by the phrase “reputation economy”
https://twitter.com/dlnorman/status/710107854091345920
The article to read is Cory Doctorow: Wealth Inequality Is Even Worse in Reputation Economies where the great writer shares some criticisms about the idea of an economy for reputation.
His first book (still on my list) Down and Out in the Magic Kingdom, centers on the idea that might read out of a few 100 startup IPO pitches:
Unlike other virtual currencies like Bitcoin, Whuffie isn’t something you buy and sell: it’s a score that a never-explained set of network services calculate by directly polling the minds of the people who know about you and your works, reducing their private views to a number. The number itself is idiosyncratic, though: for me, your Whuffie reflects how respected you are by the people I respect. Someone else would get a different Whuffie score when contemplating you and your worthiness.
“Reputation is a terrible currency” because it’s not quantifiable; Doctorow describes how it is more of a game of a popularity contest. I will step aside and let you and maybe some real economists weigh in here; read the article yourself.
The link Chris shared is her blog post on Twitter and the Reputation Economy in 2014. She finds that Klout (more or less a different spelling for “Whuffie” and LinkedIn Endorsements, promoted as measures of reputation, fail as a ‘measure of “who I am” based on what others say about me.’
What she explored as, to her, a more useful measure is un=expected. She made a list of all the twitter lists she had been added to, and made a word cloud from it.

flickr photo shared by Fleep Tuque under a Creative Commons ( BY-NC ) license
To Chris, it feels like a good measurement:
It accurately reflects my professional and geeky interests, and if you dig in there a bit, it tells you my gender, where I live, what I do for a living, some of the books I’ve read, games I’ve played, conferences I’ve attended, that I’m old enough to be on someone’s BBS list, and if I can say it humbly, that overall people have a pretty positive opinion of me.
To me it is much more of an indirect indicator of reputation, while interesting, not a measurement. Like we do in that chemistry lab, we are not actually measuring the number of hydrogen ions, we are seeing a reaction that indicates this value via a color change.
And the twitter list is even more indirect. What kinds of lists we are on will depend on our activity level, the range of things we tweet about (personal/professional/food choices!), etc. And our judgment of whether any measure/indicator works, is how well we feel it first for us.
But all that aside, I find what Chris did to be really interesting. And I was driven to try it out myself. Thus the long journey.
I will start with the end; I did get my data for twitter lists I was added to, and plopped them in Wordle.net (after the usual jousting with Java). I started playing with the randomize feature for the display settings, and thought it would be fun as a video. So I screen recorded (with QuickTime Player) my flipping the button.
Here’s what my Twitter List Memberships indicate:
I might have gotten more if I did like Chris and winnowed out the obvious education / education technology entries.
Interestingly, while Twitter well present a list of all lists I’ve been added to, the web version never gives you the number. Oddly and inconsistently enough, Tweetdeck (owned by twitter) does provide me the number:
I am on 741 lists. Who knew? (the twitter API does). But how do I get a list of them? I am not about to scroll and copy from the web page. Surely there must be some web service that does this, but no Shirley, I could not find any.
I’ve played a bit with the twitter API tools, and there is an API call that returns all the lists I am added to. There ought to be, because I’d bet my left shoe Twitter uses their own API to generate this on their site.
But there is a Twitter API console where you can run queries. You need to authorize yourself to have access the api, the Basic option lets you click authorize via the account you are currently logged into.
Under the Query tab, I need to tell them which user I am trying to find list memberships (that is me)

I belong to 741, and the docs say the default I get will be a default of 20, so I give a bigger number to retrieve (1000 is the max)
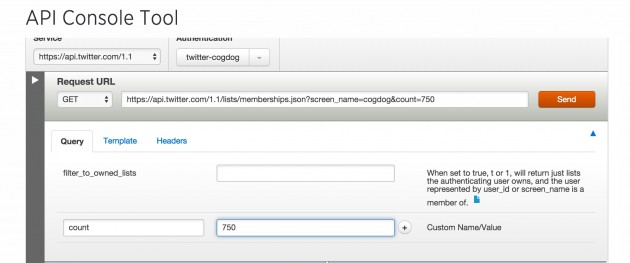
Thus my API request is https://api.twitter.com/1.1/lists/memberships.json?screen_name=cogdog&count=750 (you cannot plop that URL in a browser, because it needs to be authenticated, thus using the console).
So it runs, and if I guess right, it got the data… but it says “content too large to display”. If I read the response I should have gotten a json.json file??? I’m on a thin ledge of understanding
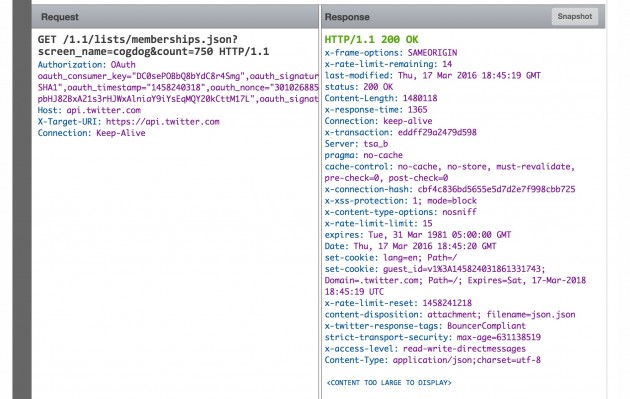
I’ve hit my edge of understanding. What to do? Call for help.
Looking for tool to generate list of twitter lists I'm on (~740 too many to scroll). Got API query; data too big for console @mhawksey ?
— Alan Levine (@cogdog) March 17, 2016
I thought Martin Hawksey might have something like this, but I got a response quickly from The Great Tony Hirst.
And did a large rabbit hole open up. A Tony Hirst lit up rabbit tunnel of wonders
@cogdog i have scripts for that sort of thing, but rushing a for boat… will try to post it later
— Tony Hirst (@psychemedia) March 17, 2016
Tony does these insanely complicated python-data-scraping-recasting data using something called iPython Notebooks. I’ve read his posts for years but never really dove in. But he provide enough pointers in subsequent tweets to get me going.
First I needed to install docker on my Mac. I am not about (or likely able) to full explain docker (this is the stuff Jim Groom and others are excited about). It is a system where I can run, on my laptop, a small server with prebuilt stuff in it that does stuff.
It’s like seeing the internet with a new pair of powerful nightscope goggles.
I downloaded the docker installation stuff for Mac and walked through their tutorial in about 20 minutes. It is one of the most well written tutorials I have seen.
And in not time at all I was installing the image for the whale-say program, then hooking in the fortune program as a pipe…
That @psychemedia is getting me aboard the container ship pic.twitter.com/zS3YQQ8yx5
— Alan Levine (@cogdog) March 17, 2016
I followed Tony’s suggestion to use the Kitematic app that came with the Docker install; it’s like an application to browse all the docker images you can download and install. I needed to install the Notebook one by Jupyter
@cogdog this one… pic.twitter.com/lDvHfHQldB
— Tony Hirst (@psychemedia) March 17, 2016
That was easy. It launches as a web site hosted locally on my machine. I had downloaded the iphython notebook file Tony had apparently made for me while on his boat commute (that guy is legend)
@cogdog you might not like the result!;-) Get yourself a jupyter notebook and try this https://t.co/h8v1dBP8KR
— Tony Hirst (@psychemedia) March 17, 2016
I upload this to my Notebook running in docker.. and it’s a code I can manipulate and run in the browser, all via a local IP address on my machine.
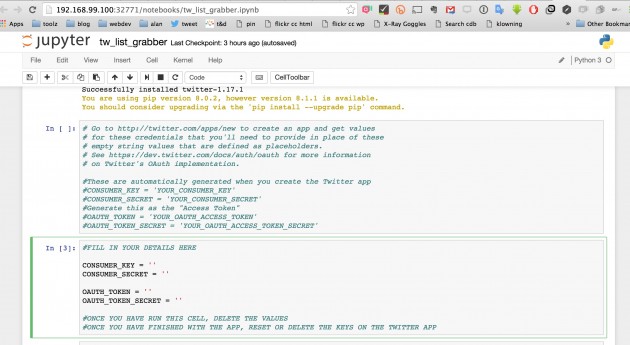
I’ve never seen anything like this, but I figure out I have to put some twitter API keys in here (I just use some existing ones), and then I use the command to RUN CELL to execute just the highlighted block of code.
It turns blue, and lights up a star. I follow the directions to delete the API keys once I have authorized in the next cell. Then I run the rest of the cells. And off it goes…

It has done some of the work, but apparently stops due to the limit how many times you can pound the API in 15 minutes. Tony re-assures me it will pick up where it left of in 15 minutes… and he’s right.
Eventually it finishes, I can see the results, and the file is sitting in my notebook area of my container.
What I have now is a text file of data that looks like:
@PawsPlease/showing-love-for-pups @vremigrant/digifest2016 @Classkick/edtech-influencers @ShootintheDirt/aphoto @MichaelLill1/instructional-designers @Metacaug/5000-2-0 @OtterScotter/open @Metacaug/5000 @Metacaug/2000 @Metacaug/a-list @awasim/mostly-tech-people @DeniseAtShear/payson-friends @I_MacFarlane/web-resources @SSpellmanCann/etmooc-participants
So the data is in the form of twitter name/list name. I will do some search and replace next, first replacing all “/” with a “,” (so I can have a comma delimited file, yes I could tell Excel to use the “/” as a marker, but hey).
I then to a search and replace on “-” to ” ” to separate the list names as URLs to be just words.
I save as a file *.csv and open in Excel.

I now can copy just the second column, and I have a list of words that represent all twitter lists I am on. I can pop this into Wordle.net (wrestling again with Java updates), and make pretty pictures.

Whew, this was a long way to go.
but get this, in pursuit of one thing (a wordle of my twitter lists) I learned to use docker and ipyhon notebooks; I have opened up all kinds of doors of possibility. This of course, is a problem when learning is all focused on specific outcomes, where is the room for the tangential learning? (that’s another blog post, or not).
And all of this is an exercise to question what we mean if we are trying to “measure” reputation. We know what it is when we experience an action based on reputation, but can we put a number on it? And if we do put a number on it, does that really mean anything?
This is what Chris recognized in her post:
And of course that’s the big problem with all of these reputation or influence measures – the algorithms can’t yet measure what’s REALLY important: trustworthiness, competence, honesty, reliability, compassion, dedication, clarity, ability to synthesize and make meaning from complexity. These are the measures I really want to know about someone, and as far as I can tell, there’s nothing out there like that yet.
The Twitter List names that people create for themselves, some of which touch on values not just buzzwords, are the closest I’ve seen to anything like those kinds of measures, which for me makes Twitter a potentially overlooked but pretty important tool in the reputation and influence measure toolkit in 2014.
I still would call it more of a possible indicator than a measure. What we do with that?
Maybe we just go spend all our KloutWhuffie in Disneyland.
Top / Featured Image: My image search was in Google Images / License for Reuse on the word “indicator”. The results were a lot of dials and meters, but not surprisingly, a few chemistry ones. Do you remember basic chemistry class, testing pH? The drops of stuff are indicators. The image I used is from a creative commons licensed YouTube video pH indicators: phenolphthalein, curcumin and malachite green

Alan
There are perhaps other ways of getting the data (maybe even through the Twitter console? I haven’t tried…) and there are also ways of getting access to free hosted notebook servers (e.g. try.jupyter.org, though I don’t know if you can pip install additional packages, or IBM Workbench http://blog.ouseful.info/2015/12/18/ibm-datascientistworkbench-openrefine-rstudio-jupyter-notebooks/) but now you have a way of running notebooks (which are magic:-) and can easily spin up your own containers (eg search for tabula – a rather handy PDF table extractor) *on your own machine* 🙂
Ah, you may say, but I *could* just download and run the app as a normal desktop app. True, but the same containers from Docker Hub can also be launched in the cloud (example: http://blog.ouseful.info/2015/02/05/getting-started-with-personal-app-containers-in-the-cloud/ ), which means if you’re in a training session and want to make the app available to participants, you can quickly pop up a version accessible on the web and let folk access it there…
Alan
Re: deleting the API keys – that was when I thought about setting the notebook up to run in the cloud (eg using http://blog.ouseful.info/2015/10/31/running-github-hosted-jupyter-previously-ipython-notebooks-as-online-applications/ ), and I wanted to preserve your privacy as far as possible…
By the by, if you download the scipy-notebook container (again from jupyter) it has a load of scientific computing libraries preinstalled.
There is also a wordcloud package (eg via http://sebastianraschka.com/Articles/2014_twitter_wordcloud.html ).
If you run:
!pip install wordcloud
in a notebook code cell (you only need to do this once), the ! will invoke a command line command to install the wordcloud package.
Now run:
#—–
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
wordcloud = WordCloud(
stopwords=STOPWORDS,
background_color=’black’,
width=1800,
height=1400
).generate(‘ ‘.join([i.split(‘/’)[1] for i in listnames]))
plt.imshow(wordcloud)
#—–
If the wordcloud doesn’t appear, run:
%matplotlib inline
in a code cell (you should only need to run it once) and then retry the wordcloud. (% things are called magics 🙂
Now you can fly:-) https://xkcd.com/353/
Can’t wait to try word clouds without stupid Wordle Java , thanks for the assists
Hey Alan – iPython Notebooks are also available at oet.sandcats.io – here’s a share to one https://oet.sandcats.io/shared/GF2aYQZmTfTN4BNUX-JAKGKhY0XOwH35V_hCeyQwfxa
Finally got a chance to sit down and read through this post, and really got a good laugh. Sorry to lead you down the rabbit hole, but it sounds like it was a fun (albeit frustrating) journey, and for my part of the serendipity chain, I blame insomniac @oldaily reading at 4AM.
You’re right of course, the Twitter lists wordcloud is not a measurement at all, and I’m glad you called out my misuse of the term. I’ll try to be more precise in the future.
Of course, the number of lists a person is on IS a measurement of just that, and that number loosely indicates: how long they’ve been on twitter, how big their network is, how many people find them interesting enough to bother putting them on a list, whether or not the kind of people who even make Twitter lists follow them. (I should make another post with my half-baked guessing about the kinds of people who make Twitter lists, but I apparently like to follow the kinds of people who are followed by the kinds of people who make Twitter lists, if you follow that.) 🙂
I had the idea to make the wordcloud in the first place because I habitually scan to see how many lists a person is on, and what words appear on the first couple pages of a person’s “added to” lists before I add them to my feed. I was looking for data to help me reliably make good decisions (!) about whether or not to follow someone, and I’m willing to invest 30 seconds to check out someone’s profile/lists before taking the risk that they’ll just clutter up my feed with silliness. For example, I am not a sports person, so if I see an interesting tweet but discover that the tweeter is on a bunch of sports-related lists, I typically don’t follow that person because I don’t want to be annoyed by tweets about the Stupid Bowl or whatever.
You point out that, “What kinds of lists we are on will depend on our activity level, the range of things we tweet about”, and that’s exactly what makes the aggregate of List terms a fairly RELIABLE indicator for finding the kind of tweeter I like to follow. It may not be a reliable indicator for anything else, though.
So my takeaways of the moment: 1) measurements and indicators are not the same thing, important point. 2) reliability is key, whether of a measure or indicator. 3) the use-case (type of decision you’re making) should drive the type of data used to make your measurement or indicator. 4) a measurement or indicator created for one use case may not transfer to a different use case.
Or something. Moar coffee needed.
Twas a wonderful rabbit hole, Ms Toque. And to me a brilliant idea to look at something that is not explicitly a contrived measure of reputation to get at a _________ of it. My takeway is that it’s not one meausre, or indicator, or collection of badges, but a medly of things that forms a picture of who someone is.
There is a full pot of coffee on the stove. Thanks for the inspiration.
You inspired yet another blog response from me when I was supposed to clean my house: https://amysmooc.wordpress.com/2016/03/19/list-lurking-as-inspired-by-alan-levine/
Loved the post. Both from the style of sharing your journey in Docker and the topic of deal with Twitter lists. All this while musing about OpenBadges for independent Learners.
See! People read these posts!
The Python notebooks are on my list from this and this.
This programistan rabbit hole is deep . . .
There is no bottom to the hole, you go down and down and emerge somewhere above another plane.
Check out Pineapple- a Mac OSX front end for iPython notebooks https://nwhitehead.github.io/pineapple/