I’m on R&R time visiting my good friend Mike in Durango. We both share a background in Geology but careers in technology, so we do tend to talk about geekery. When I showed up he gently teased that he had a project for me, and as it turns out, it was just the right size challenge to generate a few rounds of looking for solutions, and finding one in the oddest place.
Mike designs exhibits and experiences for National Parks visitor centers, and he has a need for a simple climate change display of data on C02 measurements. NOAA’s Earth System Research Laboratory publishes regular charts and stats on the measurements from Mauna Loa, the data he wanted is like the ones displayed on the weekly stats — the most recent weekly measurement, the measurement from a year ago, and that from 10 years ago.
The display is as simple as an iPad in a display, so it just needs to automatically update with the latest data.
I first looked into the raw data published in a text file format, but it’s not really structured like tab/comma delimited. I thought through a possibility of a server php script that would read the data on a weekly basis, parse out the values, and republish it maybe as JSON (and thinking something like datatables might work then to display the results.
I went back to the web site and noticed they have an RSS feed for their trends data. It’s a mix if monthly trends that are not what Mike needs, but also weekly ones, that have the exact data he asked for in the description field:
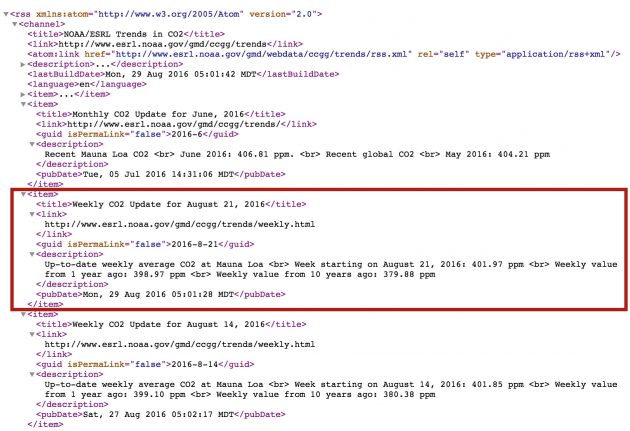
So fetching and parsing an RSS data seemed doable with client side scripting. A post by Raymond Camden on Parsing RSS Feeds in JavaScript – Options summarized a number of approaches, and the issue of some with limits on the cross domain problem (limits on what Javascript can do with data from another source).
But another suggestion had me first pause to say, “Is it crazy to use this?”, but curious enough to go explore — Yahoo Query Language. Yes, Yahoo Pipes has flushed, and they’ve just been bought at a garage sale by Verizon. But as many are eager to say, “What do I have to lose” by even exploring?
It’s pretty slick in that it allows you to run SQL like queries against data URLs, and then return the results as XML or JSON. I just wanted to see if it was possible.
What is cool is that the YQL console lets you try out data and query and see the results. There are demo queries under the DATA tab for RSS feeds.
So it’s easy just to get all of the info from the feed. And then I added a condition to look for items in the feed where the title starts with Weekly CO2 Updates. I only need the most recent item, so I can use LIMIT 1 to give me just one result. And I do not need all of the data, only the text that is in the description.
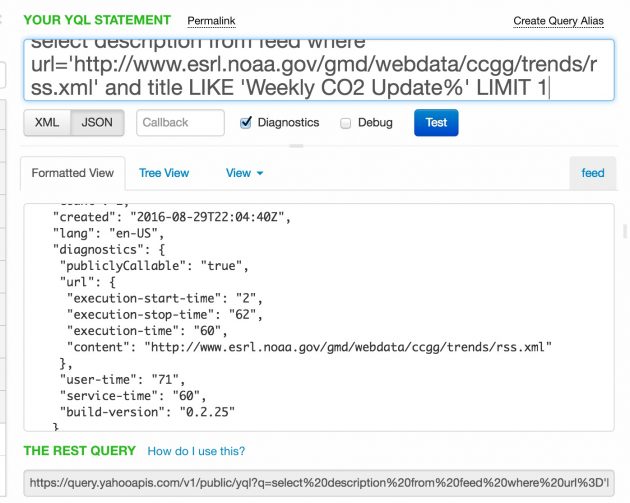
Or my YQL is:
select description from feed where url='http://www.esrl.noaa.gov/gmd/webdata/ccgg/trends/rss.xml' and title LIKE 'Weekly CO2 Update%' LIMIT 1
The JSON results can be seen via a really long URL that it generates
https://query.yahooapis.com/v1/public/yql?q=select%20description%20from%20feed%20where%20url%3D'http%3A%2F%2Fwww.esrl.noaa.gov%2Fgmd%2Fwebdata%2Fccgg%2Ftrends%2Frss.xml'%20and%20title%20LIKE%20'Weekly%20CO2%20Update%25'%20LIMIT%201&format=json&diagnostics=true&callback=
or an alias I made http://query.yahooapis.com/v1/public/yql/cogdog/c02
I found a basic example of using YQL on RSS in the documentation that was enough for me to try running it.
More or less, the script is referenced at the bottom of the HTML file, and by tacking on the name of a function in the long code for callback=output_latest_co2_stats, it means when the page load, it fetches the data, and then sends it to my callback function. Because my query has simplified the data, I do not have to loop through the feed to find what I want.
When the function is called, it sends the data from that feed item as content for a div in the page
I added some bits to add a date when the update happened, and also a setTimeout() function to reload the page every 24 hours to make sure the data is fresh (in theory I could do that weekly, but I have some doubts about a single web page waiting reload once a week). If the staff at the center notice it has not been updated a simple page reload will start it up.
Lastly, I fiddled some CSS to scale the font to the size of the display. All of the one page pony trick is available, with more comments than code in it.
Enough talk where is it? Well, because it’s just a simple web page, the logical place to hang it is in GitHub Pages, so the repo is at https://github.com/cogdog/co2 and the demo is viewable at https://cogdog.github.io/co2/
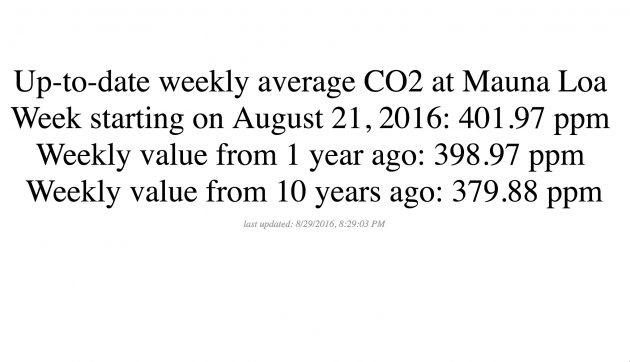
This is about 1.5 hours of thinking while dog walking, an hour of research online, and 2 hours of fiddling with the code. Okay, so maybe YQL may not be around a long time. Having done this, I can figure out other ways now to replicate that task, even if I have to roll the code myself.
But what if it is around a while? Just going through this process has me more clued in to not only other ways to do this task, but more possibilities of YQL does persist a few more years before the sun burns out of the sky.
And that’s how I have fun on my road trips. Well more than that…

flickr photo shared by cogdogblog under a Creative Commons ( BY ) license
Top / Featured Image: Sometimes I am not very sure what kind of image I am looking for, so I might just try a few odd searches in Google Images (filters set for open licensed stuff, naturally). In this case, I started first on “duct tape” thinking of how this little code thing was pulled together, then I looked for old tools, settling on “old wrench”.
I went way down the scroll to find this weird looking wrench / art piece, and it just said to me, “I am your image, now go write the thing” The photo is a flickr photo by chocmonk https://flickr.com/photos/chocmonk/7170237553 shared under a Creative Commons (BY-SA) license
