Lists of links… the desire to “curate” lists of web resources is almost as old as the web itself; in our project can we turn the output of resource collection into an open resource itself?
Bear with me on probably a bit too much back story…
Back in 1993, my first exposure into the web was primarily through the links of sites via the NCSA Mosaic What’s New Page (sadly that link leads to Page Not Found, and worse, the link for it in the Internet Archive is a dead end of redirects).

Screen shot of the NCSA Mosaic What’s New page from the Computer History Museum; listed as “© Board of Trustees of the University of Illinois” — can a screenshot of a public web site be copyrighted?

The “Bag of URLs” site I ran 1997-2005.
In my work then as in instructional technologist for the Maricopa Community Colleges, I did more than my share of link finding and trying different systems for sharing from manual coding of HTML pages, to a system of link submission/review/indexing with ancient perl scripts, and to what should have been the best, social bookmarking of links.
I was proud of the duct-taped with perl system I built called The Bag of URLs:
set up so we could collect 20-40 new sites, descriptions in a holding bin, then when ready, we had a web interface for publishing them as a new web page, re-creating the main page with the current content, and generating an email message that could go out announcing the new issue (we used a listserv so interested persons could self subscribe).
That image of a URL in a shopping bag was a reflection of what I saw many of us doing on the web– it still first. I made the image using Clement Mok’s CMCD Visual Symbols CD-ROM (I still have it) which was designed for images used on the early web, royalty free (pre-dating Creative Commons licensing).
Surprisingly, my del.icio.us social bookmarking links from sites bookmarked 2005-2006 still works! For a variety of reasons, social bookmarking waned, especially the kind where multiple people could contribute web links to a shared tag, as well as being useful for themselves. Many people claim social media fills this space (I disagree, but that’s another post). I currently use pinboard.in, which while providing this capability and more (for example, compound tags), is less widely used as it is a subscription service (well worth it, thanks Pinboard).
And this was perhaps a decade before the word “curation” was added to the name for collecting and sharing web links.
Twenty three years later, making collections of links as web pages, in Google docs, shared in social media, posted in Slack channels is all about making more and more piles. We are doing it ourselves, in researching resources for use in the Certification design.
Sometimes it literally is a list of URLs:

A small link pile for one of our units in development
but at times annotated with some description.
Yet what we end with mostly is a “blob” of unstructured data. Lists of links in static containers. It’s understandable and frankly, after all this time, to me, unavoidable.
Potentially, there is a familiar organized structure for this kind of information:
- Title of the item
- A URL where it is found
- A short description so we know what it is about, or why the heck we saved it in the first place.
For our Certification project, I could see other types of information we might want- the organization or person who provided it (for attribution), the license it was published under, a mapping of resources to the modules and units of the draft certification structure.
Again, I wonder if there is a more organized approach. I can envision when the certifications are published, our team may pick 3 or 4 recommended OERs to include, but we know there are more. Ideally we’d like to have a link that leads to a dynamic generated listing of all we have gathered, so it can grow over time.
I did some experiments with setting up a resource input form with Google Docs. Getting stuff into a spreadsheet is good, and I dabbled with tools to generate a more friendly front end access to the data with some open tools for making a front end filter / search interface (and later recast with a better tool).

flickr photo shared by CollegeDegrees360 under a Creative Commons ( BY-SA ) license
It all sounds like a good idea, and everybody supports sharing resources. But also, filling out forms is tedious, no matter how cute you try to be in the prompts, and thus the form I made has sat idle.
Having built a few javascript based browser tools, I spent about 10 minutes building one for this form based on how you can pre-fill google form items. You can drag the link on the big blue button from here to your browser bookmark/favorites bar.
This means, in your far and wide travels on the web, if you come across a resource of potential value, first try to select a sentence or two of descriptive text on the page. Next, click the bookmarklet tool. Boom, the form opens in a new window, and it automatically has filled in the title of the site, the URL, and put the highlighted text in the description.
Let’s say I have come across the Teaching Copyright lesson on Fair Use: Remix Culture, Mashups, and Copyright. Good stuff, it has ann activity that might be of use. Those first sentences are a good summary; I highlight them with my mouse, before clicking the bookmarklet tool:

Highlighting a good selection of text as a description of the site I want to share..
When the resource form opens, three of the items are already filled out for me. Holy time savings, Batman!
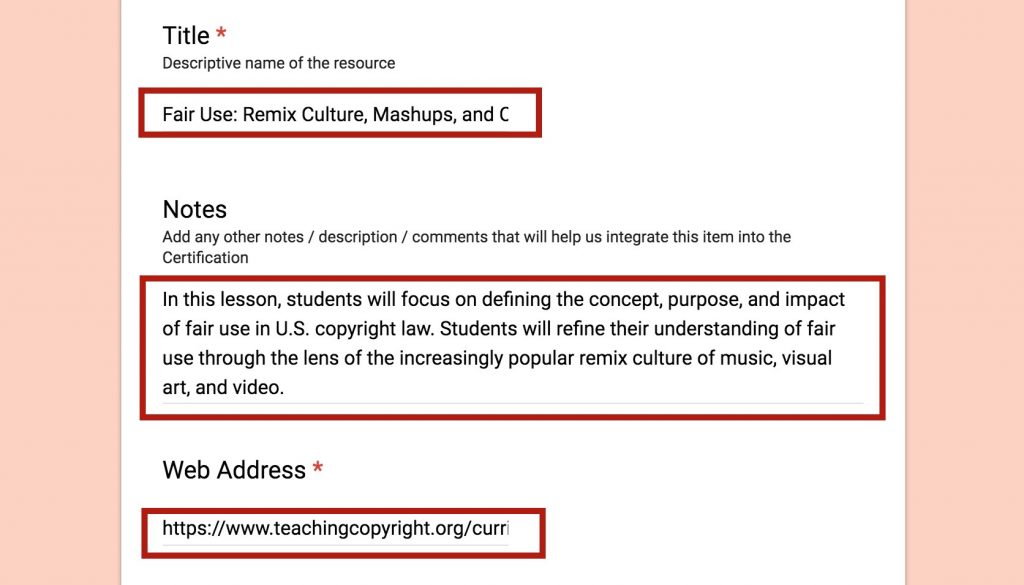
I can take a few more moments to scan and find out what license this is shared under and make suggestions as to what CC Certification, Module, and unit this might apply to.
That’s about 3-5 minutes of effort.
We do review the submissions, so it might take a day before it shows up on this prototype browser / search site:
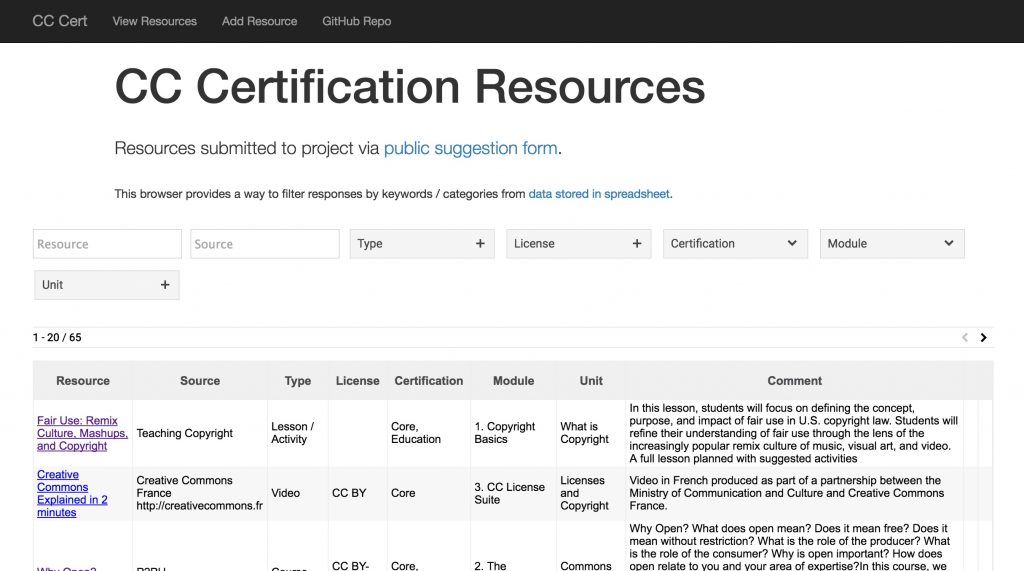
Now this kind of interface is one more for use by our team, but could be a pubic facing one as well. Or other kinds of views into the data could also be created. But because it is structured, we can do things like filter the data to narrow in on different views, each with a direct URL to the results:
- Resources for Copyright Basics Module
- All Education Resources
- All Video resources
- All Video resources for The Commons Module
- All resources for the unit on Physical vs Digital Commons
If the Google Spreadsheet turns out not to viable as a database. the data is still structured, and could be deployed in a more powerful database.
And in this way we take raw material of scattered web resources, and turn it into a resource itself. I think its useful… even as now it’s a simple concept. I dream of useful piles of rocks.
But if you have an inkling to contribute to this project, this is a rather lightweight way you can be part of the certification building.
Featured Image: flickr photo by oscar alexander https://flickr.com/photos/oscaralexander/247801526 shared under a Creative Commons (BY) license
