
Bryan Alexander recently shared his information wrangling routine, and it gives some insight to just how coherently he scans, processes, and re-shares information. But how do you categorize the serendipitous sniffing that defies such orderly processes? I find the most interesting stuff in the most haphazard ways.
Like today.
Among the twitter flow, I saw one from one of my favorite tech authors, Clive Thompson…
That @alexismadrigal and @ibogost piece is just insanely interesting folks: It's your afterdinner reading.
— Clive Thompson (@pomeranian99) January 2, 2014
among a series of hilarious funny fake sounding movie genres he tweeted. It took some digging (not too much) to find the sweeping and fascinating piece by Alexis Madrigal in the Atlantic How Netflix Reverse Engineered Hollywood:
If you use Netflix, you’ve probably wondered about the specific genres that it suggests to you. Some of them just seem so specific that it’s absurd. Emotional Fight-the-System Documentaries? Period Pieces About Royalty Based on Real Life? Foreign Satanic Stories from the 1980s?
If Netflix can show such tiny slices of cinema to any given user, and they have 40 million users, how vast did their set of “personalized genres” need to be to describe the entire Hollywood universe?
This idle wonder turned to rabid fascination when I realized that I could capture each and every microgenre that Netflix’s algorithm has ever created.
Through a combination of elbow grease and spam-level repetition, we discovered that Netflix possesses not several hundred genres, or even several thousand, but 76,897 unique ways to describe types of movies.
There are so many that just loading, copying, and pasting all of them took the little script I wrote more than 20 hours.
We’ve now spent several weeks understanding, analyzing, and reverse-engineering how Netflix’s vocabulary and grammar work. We’ve broken down its most popular descriptions, and counted its most popular actors and directors.
To my (and Netflix’s) knowledge, no one outside the company has ever assembled this data before.
What emerged from the work is this conclusion: Netflix has meticulously analyzed and tagged every movie and TV show imaginable. They possess a stockpile of data about Hollywood entertainment that is absolutely unprecedented. The genres that I scraped and that we caricature above are just the surface manifestation of this deeper database.
Well you had me at generator…
Haunted House Westerns Based on Bestsellers About Food http://t.co/wvwmDwEUYb #NetflixGenre where is raymond burr?
— Alan Levine (@cogdog) January 3, 2014
But what is truly astounding to me is the path Madrigal shares on this reverse engineering– that involved zero hacking or hard core code.
It all really comes down to someone having the ability to decode URLs.
I’ve recently come into a borrowed Netflix account… and have been rather underwhelmed at the movie selection. I do get a chuckle out of the genres Netflix sometimes tosses me (especially as the viewing habits of me and the account owner get crossed). I could have sworn I saw “Chick Flicks from Left Handed Hippie Directors Filmed in Spain in the 1980s” (okay I made that up).
But as the author notes, others had noted the bizarre micro-genres, and his first effort as setting up a google doc and tweeting out some help for people to share their own odd categories.
And this is the first step, aggregate what data gathering sites aim at individuals, then mix them together in a bigger bowl to see what kind of patters emerge.
But here is where the literacy of reading URLs comes into play:
That call for help yielded about 150 genres, which seemed like a lot, relative to your average Blockbuster (RIP). But it was at that point that Sarah Pavis, a writer and engineer, pointed out to me that Netflix’s genre URLs were sequentially numbered. One could pull up more and more genres by simply changing the number at the end of the web address.
That is to say, http://movies.netflix.com/WiAltGenre?agid=1 linked to “African-American Crime Documentaries” and then http://movies.netflix.com/WiAltGenre?agid=2 linked to” Scary Cult Movies from the 1980s.” And so on.
Get it? that number at the end is a call for a database ID associated with a genre. Change the URL and see what you come up.
For a ds106 theme, I try http://movies.netflix.com/WiAltGenre?agid=106 and get:
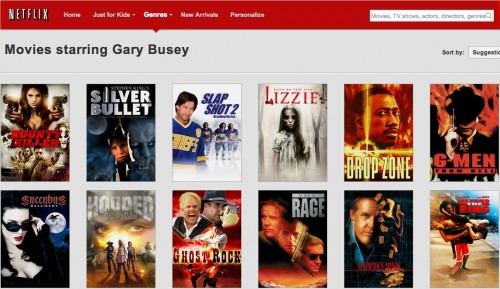
What might be the relationship between ds106 and Gary Busey? Ask twitter….
@cogdog besides drunken, disorderly conduct, debauchery, and jail time? None.
— GNA Garcia (@DrGarcia) January 3, 2014
Madrigal explored more URLs trying to find the limits, and found there was no real logical order to them. His approach was to use a scraping program with spent 20 hours incrementing and fetching URLs. More than just finding that there were 76,897 “micro-genres” he sliced the data even more to find Netflix’s “favorite subjects” or “a window unto the American soul” About Marriage, About Royalty, and About Parenthood were the top three.
The favorite decade is the 1980s, and the favorite location of movies is Europe.
He worked with Ian Bogost to create the genre generator, but then took to even further by contacting Netflix. To his surprise, there was no cease and desist, but in invitation to meet the developer of Netflix;s system, Todd Yellin,
I leave the rest of the article for you to read, but for all the waxing and warbling about big data, this example opens for me a bigger window of understanding and appreciation (and if you want to go dark you can, fear) about the way information is being sliced, diced, and served to us.
In the meantime, I am toying with several ideas how to use the generator for some ds106 daily creates.
But again, that power of someone being able to parse the meaning out of a URL? That is a secret weapon of curiosity and web literacy anyone can hone. It’s the kind of thing Jon Udell frames so well in terms of thinking like the web.
Read any good URLs lately?
Nicely deconstructed, dog.