Many of my best friends are reclaimers.
Boone is so hip he went to a dumb phone. Tim sez Ghost is better for blogging than wordpress *ASTERISK if you can get used to writing in Markdown. I mock not maybe a little– I respect these folks and their taking a stand.
I’m trying to better wrap my head around known. I have one. I’m not hip.
Myself I think there some middle ground. It’s squishy. I’m not always pressed to house everything myself, but I do want to be in control, of it. And so I think there is Claim (just do It outright), Reclaim (Take It back), and sometimes Co-Claim where you be proactive in dealing with your content being elsewhere.
And it’s not just as simple as some service boasting they offer exports of all your data. Often these end up being quite useless.
Huh?
Co-Claiming Twitter
Frankly I don’t see a need to house my tweets. I see them as completely disposable. I would not be crestfallen if they all flew away.
But I am not beholden to the limits of twitter itself. Many people know how incomplete the twitter search is. Can you find what you tweeted on July 21, 2010? Do you know every time you tweeted the word “fart”?
I do. And I did not go to twitter.com to find this out.
Among tweets about ignoring facebook planning for my high school reunion and that my vegetable garden was still producing lettuce, on July 21, 2010 I was thanks my buddy Roland for some Google Maps KML tips
Thanks @rtanglao you are right! Can use flickr KML feeds in Google map http://bit.ly/cogdogflickrmap
— Alan Levine (@cogdog) July 21, 2010
More? Since 2007, I have tweeted 57 times using the word fart (catchup jokes notwithstanding)

I have this amazing skills thanks to the genius of Martin Hawksey who crafted a way to make a downloadable twitter archive– hold the bus, you do know you can download your entire twitter history? The hitch is that you get a static archive. Martin figured out how to build one for yourself that updates itself, and does this for free sitting in Google Drive.
I call this co-claiming. Rather than limiting myself to what twitter provides or not, with some help of smarter people than me, I can go beyond what they provide us out of the box. I have my own twitter archive (http://tweets.cogdogblog.com maps to the google drive location), where I can find my own tweets either by date or by searching, all the way back to 2007.
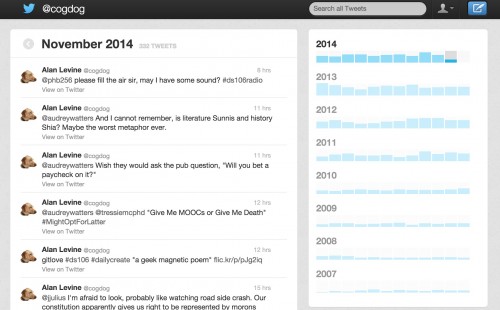
And while I hear people bemoan that they give in to the inevitable StreamMode of twitter, cause stuff just flows on by and down the drain… well, I smile. Cause I keep on Co-Claiming.
Co-Claiming Flickr
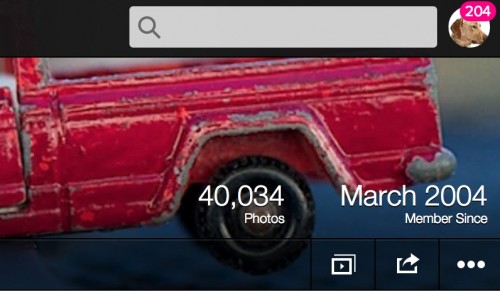
I admit perhaps a sentimental soft spot for flickr. This March will mark my 11th year of sharing photos, and look at that, over 40,000 of them. I’ve had my share of gripes, and have called their new design “an ass”. You can find a Geek Chorus singing about how flickr went south when Yahoo bought them (I am not here to champion Yahoo).
I know of folks that left flickr for Instagram, 500px, or just pour their stuff into the Grand Internet Orifice. People reclaimed their photos to Trovebox; D’Arcy went and took ’em all home (but still shares them).
But flickr to me is not about the box where the files sit. I care about the mingling effect of my photos and others. Of the contribution to the shimmering pool of creative commons photos you can search and find. I care that there are weird niches for people who share photos of graffiti in vegetation or that one dude collects photos of Rusty Mailboxes.
Again, flickr is not the definitive archive of my 40,000 photos. For a number of years I had flickr backups running at backupify; but they recently turned off the free service (there is a warning sign for you). I did get from them an 80Gb archive of my flickr photos back to almost my first ones in March 2004, but its not an archive I can do much with. The image files are there, but most of the meta data not, and I have a wobbly set of HTML pages to house them.
I maintain all my photo data in a copy of Aperture I run on my computer, with source files stored on external drives (and synced to copies). When I edit my photos in Aperture, I also write the titles, descriptions, add tags, dates, locations, even add a license statement into the image metadata… so my definitive archive is one I manage, not flickr. When I export to flickr, the FlickrExport for Aperture transfers all the data to flickr, and even writes back to Aperture the URL to the flickr page it created (read more details on my Aperture strategy).
So this might be more closely just Claiming outright, since I am managing my content in my own space.
But the point is… that if flickr bellies up, I am not out in the cold. But, unlike some of other reclaim strategies, I can still benefit form the social sharing connections inside of flickr (I can hear ya, D’Arcy, I’m letting them use my stuff for whatever plotting things they are doing with photos, I accept that.)
Claiming Medium
I’ve played some with writing on medium mostly to explore it’s interface. I noticed in fishing around the settings a link to Export Your Medium Stories to Zip. Curiosity piqued.
Well, I did get something. A folder with some HTML files in it
I’ll leave it to you to figure out how useful these are- check out the set http://cogdogblog.com/stuff/medium-export/
Check out the exported to the original

I should be thankful that I have the text; all of the images are externally referenced, and thus your archive depends on some rickety malformed CSS and links to media hosted elsewhere.
Yeah, you get an export…. WTF can you do with it?
Unclaimable Junk Jux
I was pretty impressed with the rich publishing capabilities of Jux.com — it produced web content that broke out of the page / sidebar modality. It was slick.
But apparently investors were not as easily impressed as I. A few months ago there was a notice they were closing. This had happened in July 2013, but a few months later there was an announcement that they had secured financial backing. Look I can find this in my tweets!
Stoked that July 2013 news http://t.co/jSqBIwoKve closing was wrong. One of coolest web pub formats. Getting back to https://t.co/BBPsuMBFkN
— Alan Levine (@cogdog) January 9, 2014
Well that part is now over. A week ago many of us got a Dear Jux letter, they were folding their tent and going home

Just so you can read and search on this…
Our Time is Up
We want to thank our amazing Jux Community members for supporting the platform for nearly 5 years. Unfortunately, the costs to maintain the infrastructure have become overly burdensome for our generous supporters, so it is with great sadness that we announce the closure of the Jux services platform at the end of November.
We realize that some of you have media stored on the Jux servers that you would like to preserve, so we have a link for you that will enable you to retrieve and download all your stored media files with one simple step. Visit farewell.jux.com and sign in with your Jux credentials to export your media files.
For those of you that have linked domains or other portals that depend on the Jux platform, you will need to move those links or services to another location as Jux will be going offline completely at the end of the month.
Again, we thank you for your support and wish you well.
We’ve heard these laments many times before. With the cheaper than dirt costs of cloud computing, how can it be so burdensome to keep at least existing content alive? How come they never tell us what those costs are? How do we know they didn’t shoot their IPO wad on pizza and cigarettes?
I’m not really caring about the few things I hung on Jux. Anything there I have elsewhere. But I was curious about this export process. What do you get? Visit farewell.jux.com and sign in with your Jux credentials to export your media files.
So I went to http://farewell.jux.com/. Signed in with my Jux credentials.
And got this.

I get bubkahs from Jux.
I tried back later. Three different times. Bubkahs. I emailed them at operations@jux.com. Twice. Bubkahs again. I’ve tweeted them.
Ahem @juxdotcom Been a week; I still cant download promised archive. No reply to email #whatTheJux pic.twitter.com/ai30uvhngv
— Alan Levine (@cogdog) November 10, 2014
So this is what you face in 2014 when some company offers you free hosting of your content for their Snazzofish site. This can be you a few years later, wondering why you cannot get your exports out of Snazzofish, or if so, what you will do with a pile of HTML files.
But fear not. When one Jux By Night site folds, another pops up.
@cogdog we provide an alternative platform to Jux with better features, care to check us out and give us a try?
— MyBizziBlog (@MyBizziBlogCom) November 6, 2014
@cogdog our platform is alot more durable. Check out our features, bloggers can even earn money from their posts as well.
— MyBizziBlog (@MyBizziBlogCom) November 6, 2014
@MyBizziBlogCom trade one 3rd party web silo for another that went poof? No thanks. I'm a #Webreclaimer but good luck…
— Alan Levine (@cogdog) November 6, 2014
@cogdog We also think our platform will also be a great fit for a review on your blog.
— MyBizziBlog (@MyBizziBlogCom) November 6, 2014
As soon as someone tells me they think I should review their stuff on my blog, that is my cue to exit the conversation, though the most persistent ones end up in my roach motel.
I do not know what decade MyBizziBlogCom thinks this is– what they offer might have been lukewarm interesting in 2008, but cannot possible see, in light of this WhatTheJux behavior, why anyone should put their content in some goofball blogging platform.
I call this “Preclaim”, dismissing stupid web services before even clicking the link.
Coda
I am not sure why I wrote “Coda”. Oh yeah, this is the end of the post. I should have some final statement.
Considering where our “stuff” goes and what gets done with it, is paramount, and one wears much more cynicism then we did 10 years ago. But at the same time, if we are savvy, and networked, and no clever chaps like Martin Hawksey, well we have some grounds to deal with even the services we do or cannot “reclaim”.
I’m a Sometimes Co-Claimer, Maybe Leaning to be a Reclaimer, but largely… a Com-plainer.
You? Are you just at the whim of Twitter? Flickr? Jux?
That’s the beauty in this internet game. You get to pick how you want to play. Although many people just keep taking just the defaults handed to them.

creative commons licensed ( BY-SA ) flickr photo shared by thepeachpeddler
(I have no idea why creepy baby head is tagged default in flickr. Again, the weirdness there I dig).

I made this. I give myself permission to reuse it. You too.

This resonates with me. Depending on my purposes, I feel I can still retain a lot of “agency” using third party systems. I gain connections and all that comes from them at what is, to me, a rather low cost. I use flickr in just the same way you do. When I was still Twittering I used TweetNest to create an archive much like yours.
It might offend the purists, but I reason that the amount of value the third parties derive from me as data is greatly outweighed by how I am using them to achieve my own ends of connection, communication and creation. Even the supposed origin of web malevolence, Facebook, has resulted in some connections and friendships that have more than made my participation there worthwhile and I value the easy, incidental contact with friends and family that use it.
The whole thing about “reclaiming” is much like arguments about book publishers and music labels and pretty much every entity that has a monetary interest in distributing creative work: there are downsides and upsides. One picks and chooses. One, I now know, co-claims.