All of my web work from 1992-2006 at the Maricopa Community Colleges was wiped from the web after I left. It was big pile of stuff for sure but it was the first of several experiences which informed me that institutions care about preserving the web much less than individuals.
But when I left that position I took a copy of every web thing I made on a 20 GB hard drive, it now takes two Apple dongles to connect to my laptop, but it’s all there.

The Apple Double Dongle Dance flickr photo by cogdogblog shared under a Creative Commons (BY) license
I have been reclaiming them on my own domain at http://mcli.cogdogblog.com/
The plain HTML stuff of course works great. There was a period, maybe I can call it Web 1.4, when I started building sites that were more like mini database driven sites, without the database.
These were resource sites where I could have web forms to add content, other other ones to search it, even generate RSS feeds. The technology was primitive- data was stored in tab delimited text files, openly writable so other forms could add to them (that’s likely why my stuff was removed, a security nightmare), and some unix program that made it searchable, I think called gais index my student worker Kurt figured out.
One was Community College Web (wayback link), where I collected and made searchable over 1200 community college web sites

I’ve not resurrected that one, but one I think I did after. I was nudged a bit a few months ago when Jim Groom was calling for examples of educational sites from the early web of the 1990s.
I was able to send a few of my own (thanks Jim for sharing them!) but remembered that one of my sites was specifically that kind of collection- Teaching & Learning on the WWW (wayback link).

While the wayback link gives you a peek, none of the search works because it’s tied to long gone perl scripts.
The vintage 1990s HTML design of the site still works fine, despite use of frames, tables for formatting, and a CSS-less pile of font tags. You go HTML.
But more importantly, opening my little disk of archives, inside the web content folder for the site was the plain text list file with all the site’s data. I was mulling recently maybe I could make it searchable again using some kind of conversion to JSON, but then remembered a simpler approach to pull off.
This awesome tool works with data stored in Google Spreadsheets creating functional ways to present them embedded into a web page. There was just a bit of cleanup to import the tab delimited text data file I had into a Gdoc spreadsheet.

The second row defines in Awesome Tables how to handle the data when displayed – StringFilter provides a search box to filter a column while CategoryFilter uses the values to populate a drop down menu.
The Wayback link was an idea I added since many or maybe all of the original links are dead, so I rig together a formula to build a hyperlink HTML column. It’s easy to build a direct WayBack link to a site, say for http://cogdogblog.com you put it after http://web.archive.org/*/ and my formula for row 3 will yield something like Go.

Ah but you are wanting to see it in action. Almost there. I had to add some notes to the original site to indicate it was an archive, change out some of the original search form that was on the left side (but I did manage some JavaScript to make the dropdown menus for the subjects hit the awesome tables page with that category pre-selected.
Ok, enough talking here is the rejuvenated, reclaimed collection of 900+ ways the web was being used for teaching & learning in the 1990s – http://mcli.cogdogblog.com/tl/
But the awesome part is the new search interface
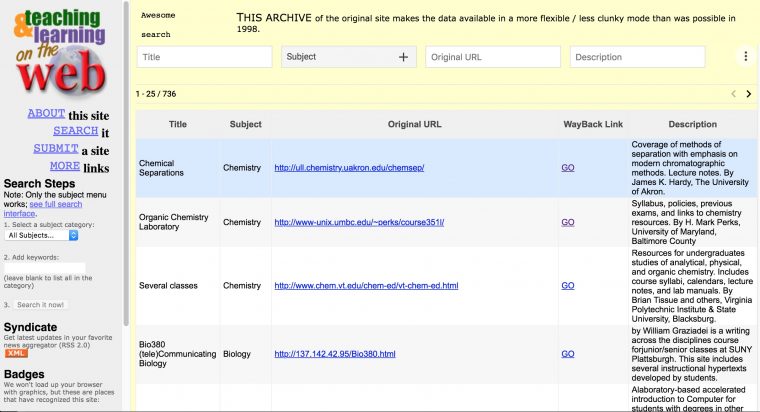
It’s pretty slick because you can filter the data with the controls for each column, and do much more fine grained searching then before. Like I can first filter for all sites with Interactive in the title and then limit to ones on the Biology category. It’s all dynamic, we stay in the same page.
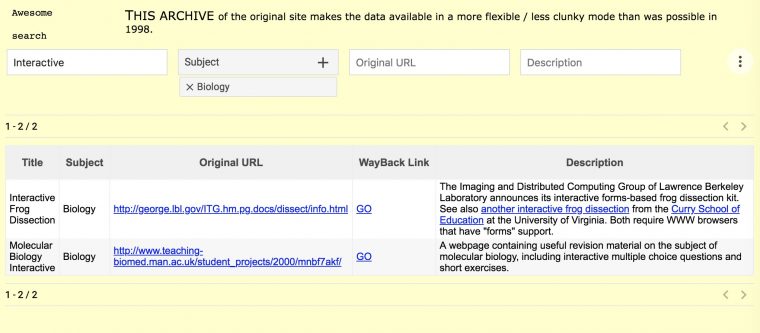
But wait, there’s more! Jim Groom has a great fascination with the early web work done in the personal tilde spaces at academic institutions. In my new iteration of my site, I can filter the Original URL column by ~ to see that from my collection, 104 of them (10.6%) were tilde space sites.
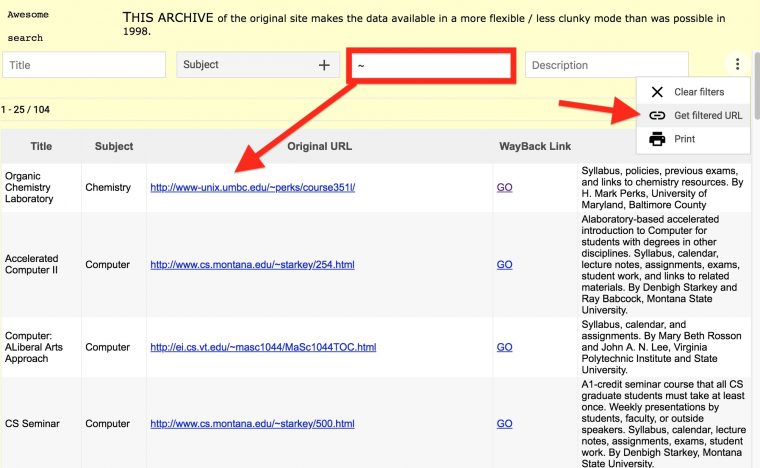
And here comes more coolness- under that … menu in the top right, Awesome Table provides a means to share this search as a URL- so you can examine the same results via
https://awesome-table.com/-LUsgFliTDek9Y1f8AFT/view?filterC=~
It renders on their site, but still… I think it’s… well to be corny, Awesome.
I cannot fully explain why I spend time reclaiming my web sites from the 1990s (check out How to Be a Web Hound and What a Site all stuff that is dated, but, heck, that’s letting you get a sense of the web of the 1990s as I experienced it.
Or just groove on my awesome logo

And no one is going to yank that site from me- it’s now cemented at http://mcli.cogdogblog.com/tl/
Featured Image: In background is 06-01.gif flickr photo by Paolo Attivissimo shared under a Creative Commons (BY) license. Superimposed on top is text generated with the nifty Make Word Art site

I don’t have any live HTML versions of the sites, but we built for-credit online courses at the Faculty of Nursing in 1995. Good times. CRINGE!
http://ancient.darcynorman.net/nursing/screenshots/nurs539-home.png