For the obviously obvious statement, WordPress is built on a database. The question is, besides data like visitor counts, what can you infer from the data in the posts and metadata itself?
The question was swirling in preparation for a research interview I did today with David Porter and Valerie Lopes for the Ontario Extend project.
My cartoon lightbulb went on over my head, thinking about that we have a blog syndication hub set up, and because of the way Feed WordPress does it’s thing, it means a copy of all posts is saved locally on the site.
I already have it display for any list of the blogs, like all of them, a count of the number of blogs subscribed too as well as the total number posts syndicated in:

Just some numbers…
This is done as well for each of the cohorts, since posts for each are assigned to a designated category, like the blog list for all in the West Cohort.
The lightbulb as that quite sometime ago, I actually built a plugin for exporting data from posts in a category, I have my own tool– wp-posts2csv. The plugin allows you to choose the category to pull data from (or just for all posts)
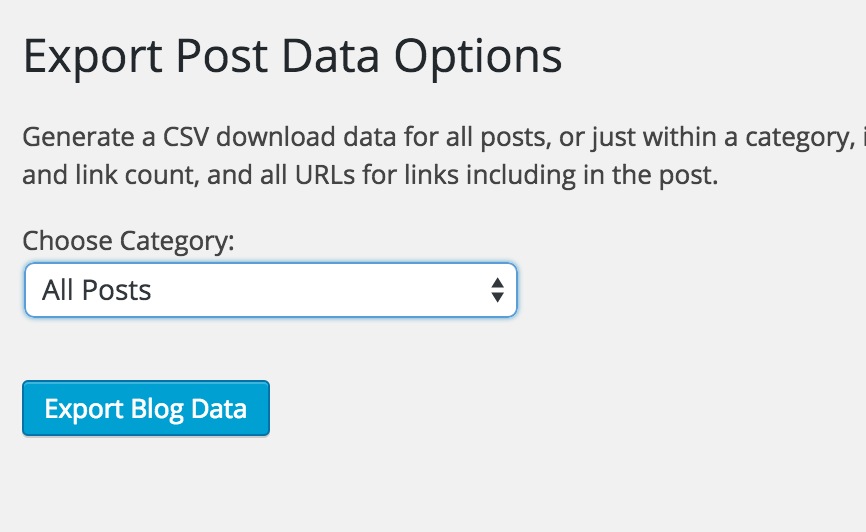
And a button to click. It returns a .csv file to download.
The thing I never was quite sure (insert disclaimer here of not being a data scientist) what is useful in having here, in spreadsheet format:
- post ID
- source indicated (either ‘local’ or ‘syndicated’)
- post title
- publication date and time
- author name (first and last name from profile, this is added to user profiles via the gravity form signup thing I built)
- author username on site
- blog name (host blog or remote blog if syndicated post)
- post character count (string character count after HTML stripped out)
- post word count (after HTML stripped out)
- number of links in post (count of ‘‘ tags)
- list of hyperlink urls (from all href= tags, hoping my regex is on target)
Here is a peek at the data (showing for two of my posts, I give myself permission to use my data about my blog in a blog post on my blog).
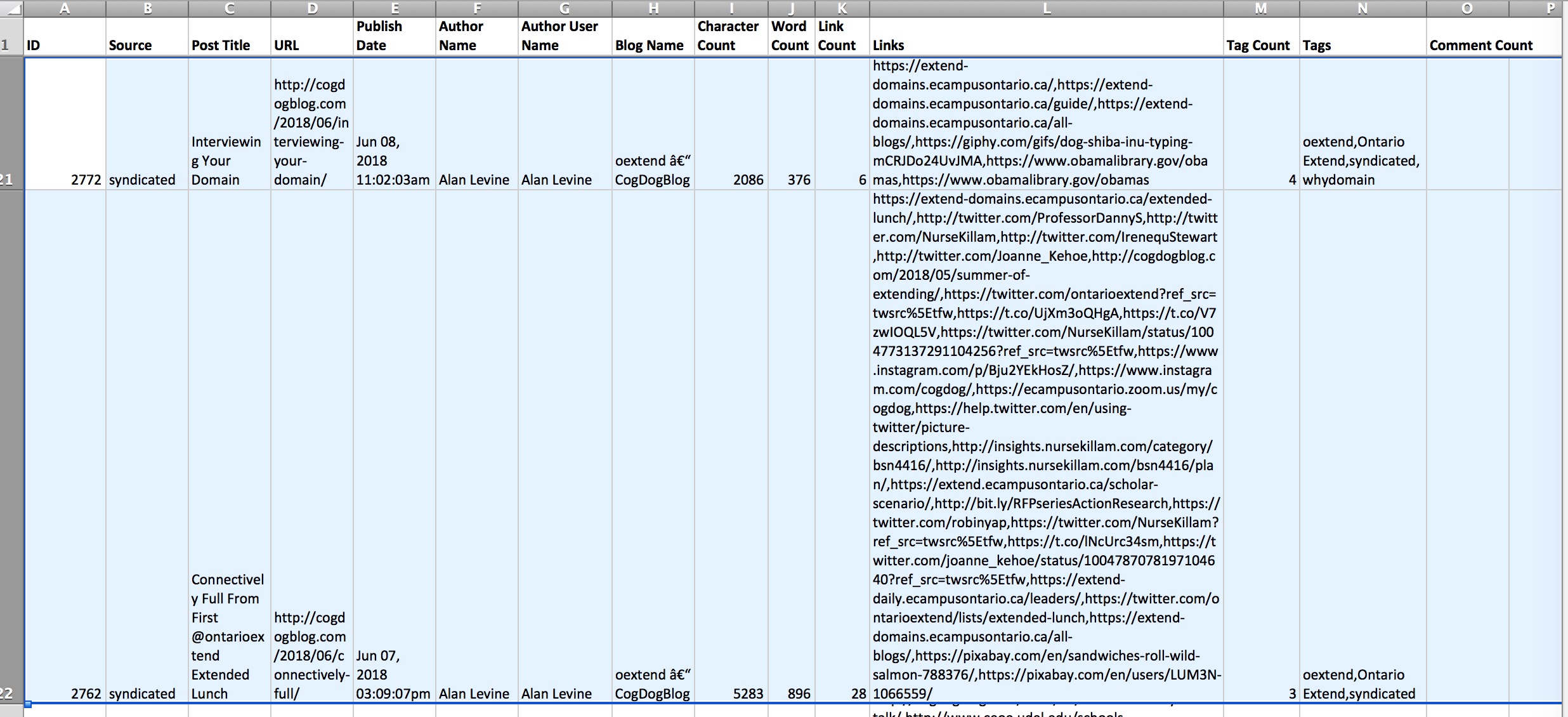
Mmmm look at all that data…
I had designed this first, and used yesterday, for syndication hubs, but it would work fine on any WordPress site. By “work fine” I mine it will spit out some spreadsheet stuff.
But really, what can one infer from this? Is there meaning in looking at word/character count? Use of tags? Use of links?
I dunno (remember the disclaimer)?
I did the due diligence of some googling, where first you have to find out how to filter out all the SEO seeking and marketing stuff, the best searches I found were for content analysis of blog posts but that seemed dusty too. Studies that referred to old horses like “technorati” and done in the mid 2000 to late 2000s.
A few focussed on comment data, which is something we do not get when syndicating posts (long story, it’s really messy).
I’d like to think my search skills were weak here, so I go Lazy Web and ask for help. What can you do with this kind of data? What else is worth getting to do activity/content analysis? Does anyone really know what time it is?
A long standing curiosity is that DS106 has been syndicating in content from thousands of blogs for tens of different classes since 2011. The tanks deep inside the database have copies of 79,000+ syndicated blog posts.
How many research projects have taken on looking at that data?
Near as I know… zip.
I guess there’s no interesting data there.
Featured Image:

toolbox 0310151652a flickr photo by ..Russ.. shared under a Creative Commons (BY-SA) license

Hi Cogdog,
Here are some things I think might be interesting to look at:
Early Birds vs Night Owls = how many posts were uploaded between 9 am & 4:59 pm; 5 pm & 12:59 am; 1 am & 8:59 am?
Weekend Warriors vs Just another day at the office = how many post were uploaded on the weekends?
Words do count! What was the least number of words, what was the most number of words? Set up some ranges within those two numbers. Chart it, which ranges do most bloggers fall into? I going to guess bi-modal (is that the right word? I don’t know)
Tag, you’re it! What about a chart of number of tags? 0, 1, 2, 3, 4, 5, 6 or more?
Why would I look at this? As a brand new blogger, I would use the information to compare my own practice. If I am posting mostly on the weekends and in the middle of the night, might be nice to know that others do that too. If my posts are all very wordy, perhaps knowing that I am on the high end of the word count will lead me to find ways to be more consise (probably not, if it is me). If I am not tagging (or tagging too much), this information may give me ideas.
This is not to say that there is any one answer to blogging but until we look at the data that shows up, we won’t know what it tells us.
By the way, I would totally do this. I love data.
Irene
Along with Irene’s excellent suggestions I’d add:
(1) something quite dull about usage over time could be extracted that could be useful for capacity monitoring.
(2) analysis of links might reveal interesting things about multi-modal blogging and/or use of social media – I’m thinking evidence for networked scholarship, or perhaps identifying key influences at a macro level above individual blog posts (are loads of people referencing @cogdog tweets for example)