Without tossing too many acronyms your way, the WordPress REST API allows you to use WordPress to create, manage content in a way that is easy for normal humans who run and scream at the site of GitHub Markdown. But you can then tap into, access, fully grab all the data to use in anyway you that think of in sites, applications outside of WordPress.
But it’s been ticking in the back of my mind for a time to use on a bigger scale.
That ticking got louder in the early planning of the CorrLeader project, especially as my client explained a desire for some efficient ways to keep busy managers tuned into new resources, opportunities from the web site, something more than email or making them return there. Especially something that would be efficient and useful on a mobile device.
I could see in my mind early, some kind of small footprint web site using HTML/Javascript to load the newest content from the site via the API, and having ways that it could be filtered to show items of the most interest.
It happened.
Again, all of the content originates from the full WordPress site (which because of the responsive theme does itself play well on a mobile).
WordPress version
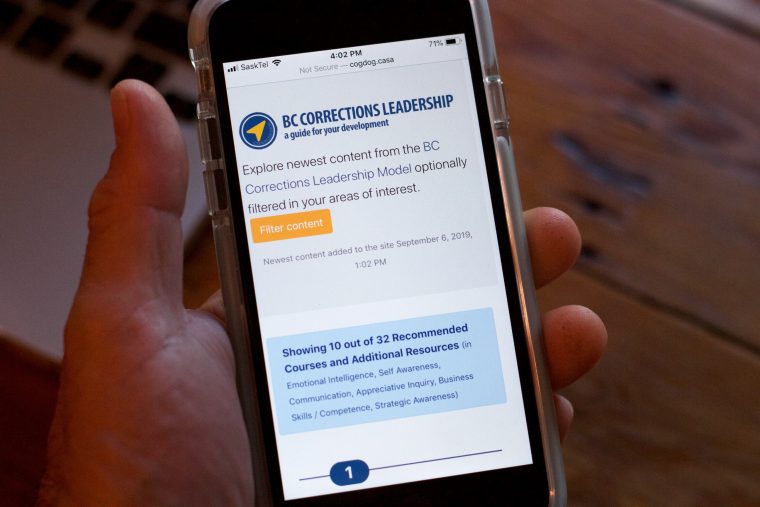
But the CorrLeader Navigator gives it to you in a compact newest content first form factor:
The navigator opens…
When it launches it has within the JSON formatted summary of all posts and custom posts types on the site (currently 84 entries, weighing it at < 1 MB).
The default view is a text excerpt summary, showing the content categories, and the link to see the full content on the main site.
Quick summary view, good for scanning new content.
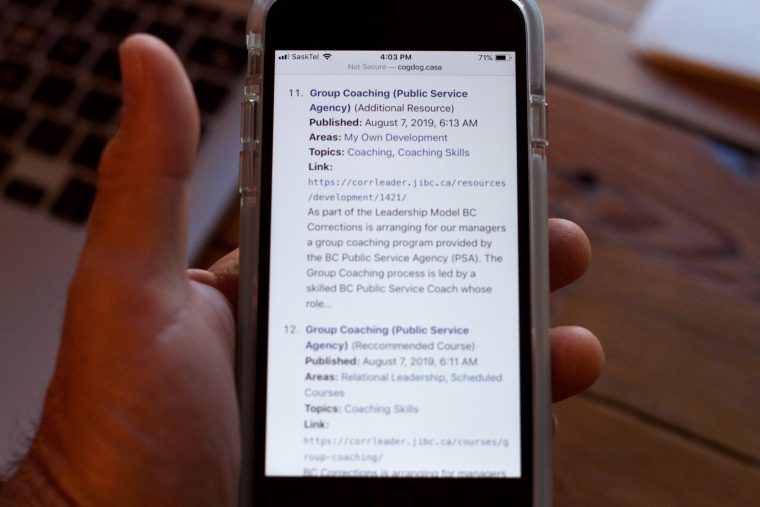
Just recently added is an option to see a full formatted view of content, images, embedded media, links, and all of the entry metadata.
Full media content view, below the scroll is the full text of the item plus the meta data.
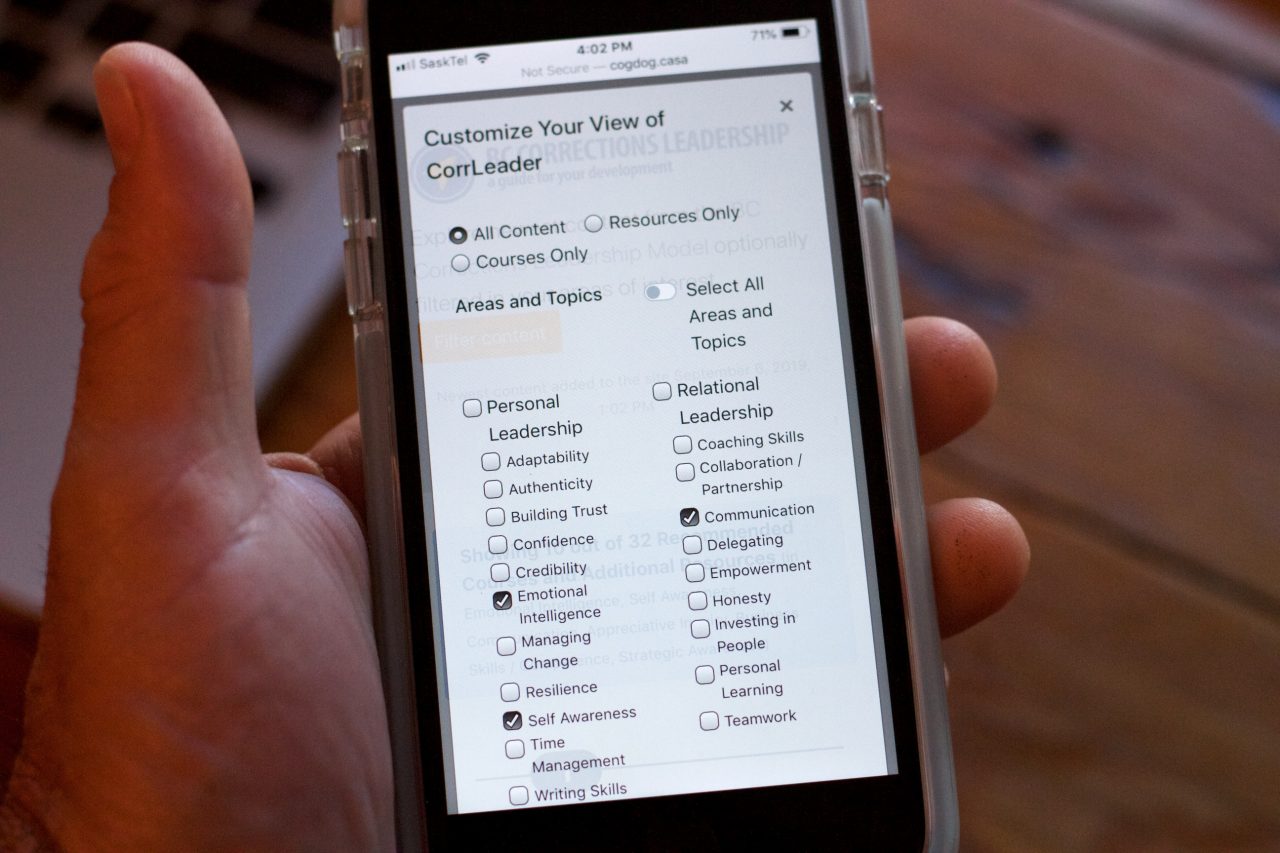
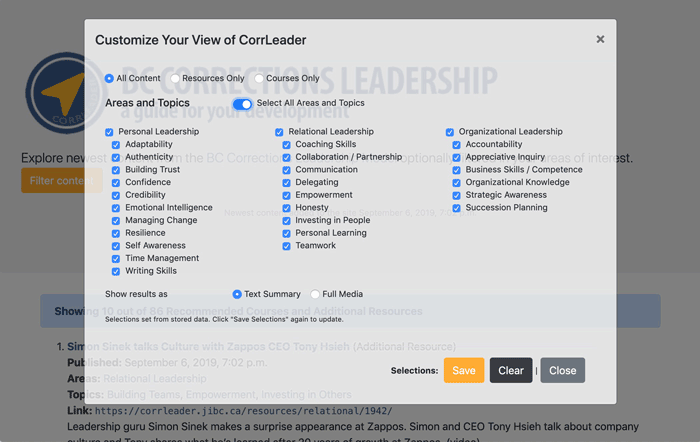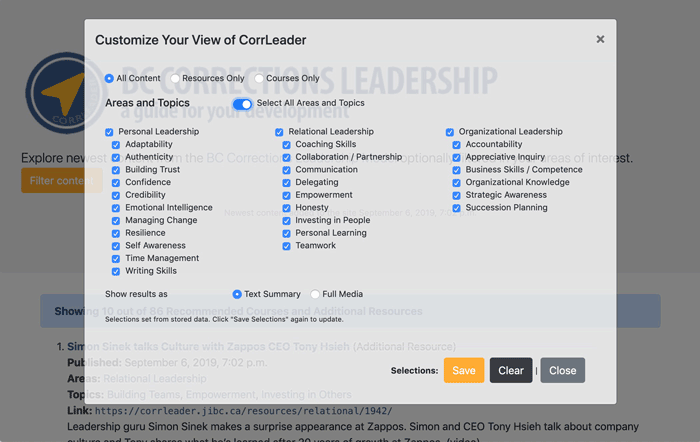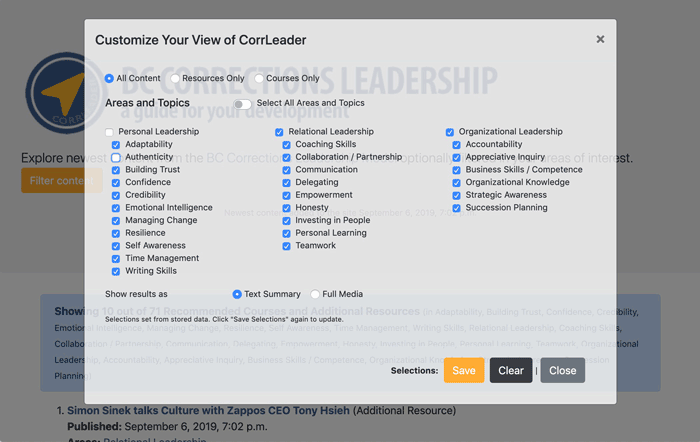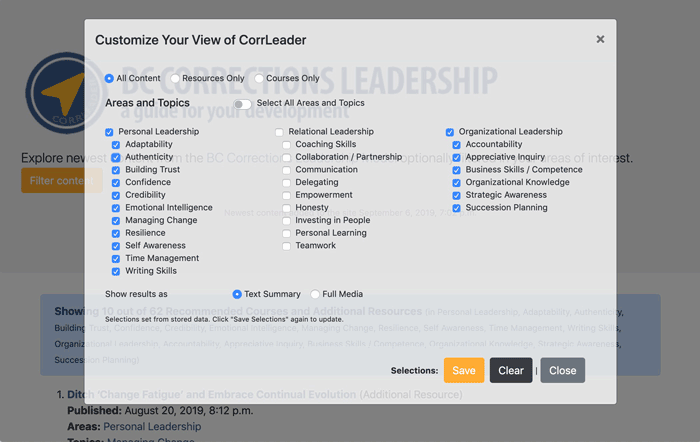
But the nifty stuff is under the filter button. Here you can select the types of resources to view (between the two content types), and then restrict by broad topic areas (Personal, Relational, and Organizational Leadership) and/or the specific topics within. I have been calling this privately Alan’s Insane Checkbox Project.
All kinds of checkboxes and buttons to customize the type of content
The results change in real time as you toggle things on and off (this is the jQuery voodoo happening inside).
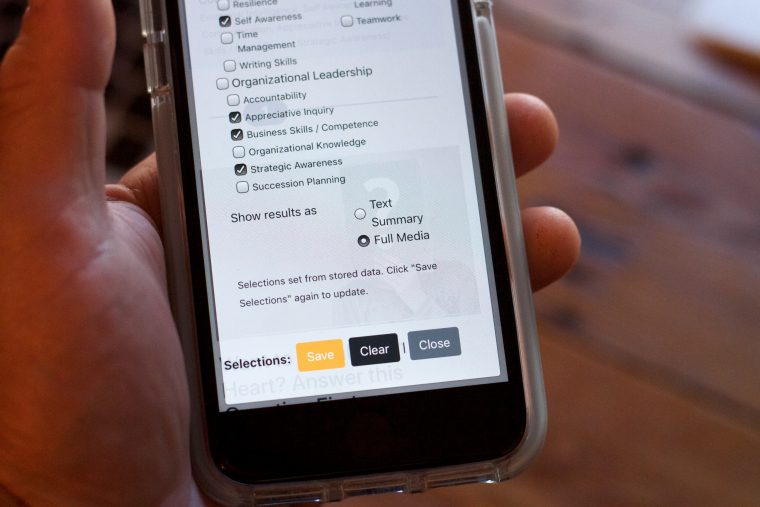
But this is not everything. What I dreamt of was a way that on your own device, it could remember your selections, so each time you flipped open your device, it would show the newest content according to the selections you had saved (no need to return to the form).
This works now.. and it does this with no trackable cookies, but using Javascript Local Storage. a means to save preferences in a way that stays on a device (a web site cannot sniff it, the data is not sent back and forth with the HTTP requests).
Navigator options to view results as text summary or full media, plus the options to save the selections in the devices local storage, so they are preset whenever you return to it. And you can also clear storage at any time.
It’s allo working now, and since setting up a means of caching the json files it loads really quick as it does not need to hit the WordPress site every time it is loaded.
That’s what it does, now for the peeking under the hood (warning, code lies ahead). Are you ready, Scotty?
Promise Me Some API Data?
The first thing to do was finding out how to pull in WordPress data via the API. The most basic call to get data on all your posts (and yes, you can try this at your home blog) is tacking on wp-json/wp/v2/posts to your WordPress blog URL. Try mine https://cogdogblog.com/wp-json/wp/v2/posts
It makes a bit more sense if you copy all that stuff and put it into something like JSON Pretty Print
This makes it much easier to see what kind of data you get and how it is organized.
The first basic test was a simple getting of this data and popping it into an initially empty div in the html page. For fun it uses backstretch.js for a background image and a google hosted jQuery library.
The first test site, victory is just getting data and displaying it.
I used pretty much the same ajax code as before to get the WordPress data.
$(document).ready(function(){
$.backstretch('background.jpg');
// Let's get some data!
$.ajax({
url: 'https://corrleader.jibc.ca/wp-json/wp/v2/posts',
jsonp:"cb",
dataType:'json',
success: function (result, status, xhr) {
var list = "
";
for (var i = 0; i < result.length; i++) {
list += '
Fortunately I was thinking about this early and had requested the site setup to include the WP REST API Controller plugin – this allowed me to expose api URLs for the custom post type and it’s own taxonomy. I now have a way to get to this data,
And now I can get this data with a second API URL, https://corrleader.jibc.ca/wp-json/wp/v2/portfolio
Here was one of many times Tom Woodward stepped in with a big help (via twitter DMs) in helping me figure out how to get the data I needed. By adding ?embed to each API URL I am able to get much more data per item (like featured image URLs) but more importantly, all the associated taxonomy data. And my including a second parameter per_page=100 I can get more than the default 20 results. I believe 100 is the limit, bit for now we are okay with 67 resources and 17 custom post types.
And the complexity grew. I had to make 2 API calls to get this data, then combine them all into one array, and also sort them reverse chronologically.
Tom again was a big help by sharing some examples of the Javascript promise constructor, which even after getting it to work I may understand about 10%. Because the fetching of the API data is asynchronous, I needed I was to wait before both were returned before doing anything (Javascript will just keep chugging along).
What I do below is first create some empty arrays to store my resources data and my courses data, then use promise to get data from both URLs, it waits until it has results to checking them and passing on to a function that displays the results. This is the basics of this portion:
// create holders for future content
let results_posts = [];
let results_courses = [];
const urls = [
'https://corrleader.jibc.ca/wp-json/wp/v2/posts?_embed&per_page=100',
'https://corrleader.jibc.ca/wp-json/wp/v2/portfolio?_embed&per_page=40',
];
// get json data via promises
// via Tom Woodward and https://w.trhou.se/bhriv87fql
Promise.all(urls.map(url =>
fetch(url)
.then(checkStatus)
.then(parseJSON)
.catch(error => console.log('API fetching problem!', error))
))
.then(data => {
let counter = 0; // simple toggle flag
data.forEach(function(results){
// crude but works to load the data in correct arrays
counter++;
if ( counter == 1 ) {
results_posts = results;
} else {
results_courses = results;
}
})
// load the results
update_results();
})
// --------------- json utilities ---------------
function checkStatus(response) {
if (response.ok) {
return Promise.resolve(response);
} else {
return Promise.reject(new Error(response.statusText));
}
}
function parseJSON(response) {
return response.json();
}
I would certainly lose the 3 readers left if I went into more detail of the update_results() code- it does a lot. It has to check if we are displaying all results, or just one content type, and if we are filtering by categories (see below), it then munges through both data arrays, puts them into a new one of they are meant to be shown, then call a funky function I found that sorts them by the data value inside of them.
Anyone there?
I learned some crazy new JavaScript methods to do this stuff, like array intersections.
Oh, I had also started using the basic Bootstrap template to create the visual part of the site. It comes with a lot of built-in features like modals and grids and buttons and more that simplified the layout part greatly. I did not want to overly stylize the output, but wanted it to look good regardless.
(I also change the CDN links for the theme and jquery to local files, just cause sometimes I like to do dev work when the internet is missing).
Those Crazy Checkboxes
The next chunk of time was spent sorting out the form interface for the customization screen. I played with a few ways to make this appear in Bootstrap- cards, accordions, and settled on the button opening a modal dialog.
The challenge was making all of these work for a set up of three top level categories (leadership areas), each with 6-11 sub categories (topics), and a master switch to allow selecting all or none.
This means if you start with all of the options selected, clicking any of them needs to turn off the master select all switch (and if all were reselected, turn it back on). If one of the 3 area checkboxes were turned on or off, it would have to turn on / off all of the sub category topics. I all sub the category topics were then all turned on (or off), then the parent category would need to match.
It was a bit like playing with the holiday lights…
The key were was using a series of CSS classes to the checkbox elements, so jQuery could act on all similar boxes. These classes included:
leader-cat any checkbox that is a category
leader-area for the top level three categories (Personal, Relational, Organizational)
leader-topic for any of the sub categories (e.g. Adaptability, Authenticity, etc)
leader-personal, leader-relational, leader-organizational to group the subt topics with their parent
triggr – any form element that would need to have the functional called up update content displayed
Or, in the context of the form:
And, as spelled out in the HTML code for the form:
It gets even trickier, because each category can be mapped to two different WordPress taxonomies- the ones for Adaptability are 16 for the Category ID for a Resource while it could be 55 for the Course Content type Taxonomy.
Crazy?
The form element for select all /select none uses a BootStrap custom-switch to change it to a slide on/off button and is marked with a CSS id of #toggle_cats.
Thos code turns all checkboxes on or off to match the #toggle_cats switch state:
// makes the category checkboxes sync to the "Check all" one
$("#toggle_cats").click(function(){
$('input.leader-cat[type=checkbox]').not(this).prop('checked', this.checked);
});
So this little gem turns this item on if none of the subtopics are turned off!
// check all topic checkboxes
function checkAllTopics() {
if ( $('.leader-topic').not(':checked').length === 0 ) {
$("#toggle_cats").prop('checked', true);
}
}
And this code handles the syncing of the Personal Leadership area check box with its subcategories:
// if any category checkbox is de-selected we turn off the select all one
function toggleCatsOff(obj) {
if (! $(obj).prop('checked')) $("#toggle_cats").prop('checked', false);
}
// manage state of personal area checkbox, if checked, all sub categories are checked
$("#personal").click(function(){
$('input.leader-personal[type=checkbox]').not(this).prop('checked', this.checked);
checkAllTopics();
toggleCatsOff(this);
});
And something like this for any sub category in Personal Leadership manages to keep the parent category checkbox set correctly
//manage checkbox states for a personal leadership topic , sync with parent area checkbox
$(".leader-personal").click(function() {
// deselect the parent if this unchecked
if (! $(this).prop('checked')) {
$("#personal").prop('checked', false);
$("#toggle_cats").prop('checked', false);
}
// if all checkboxes checked, then check the parent h/t https://stackoverflow.com/a/5541480/2418186
if ( $('.leader-personal').not(':checked').length === 0) {
$("#personal").prop('checked', true);
}
checkAllTopics();
});
Now that I am trying to explain all this, I might be even fuzzy how it all works. Believe me, I spent a lot of time checking and unchecking boxes before they even did anything!
This nifty function is used to get the values of all selected category ids, remember that there are two values in each form element, separated by a comma, which we then join then split! The .map(Number) turns out to be needed to get the values not as strings.
function get_selected_cats_val() {
// return all the values of selected category checkboxes, each with a comma separated set of vals
// Join results as into string array, then split back to arrat, convert text to integer
// h/t https://stackoverflow.com/a/6116631/2418186
return($("input.leader-cat[type=checkbox]:checked").map(
function () {return this.value;}).get().join(",").split(",").map(Number));
}
More helper functions to get the ids of selected categories and the names as well (extracting from the labels of checkboxes).
function get_selected_cats_id() {
// return IDs of selected category check boxes
// h/t https://stackoverflow.com/a/6116631/2418186
return($("input.leader-cat[type=checkbox]:checked").map(
function () {return '#' + this.id;}).get().join(","));
}
function get_selected_cats_names() {
// return names of selected category check boxes
return($("input.leader-cat[type=checkbox]:checked").map(
function () {return $(this)[0].labels[0].innerText.trim();}).get().join(", "));
}
What About Showing Stuff?
The .triggr class on a form element has a function that calls update_results (which is also first called when the page is loaded). This is the kind of code that grow like spaghetti over time. Let’s walk through the pasta.
We start with a start value! This indicates where in the array of results to start walking through to get data. Default is 0, meaning form the beginning, but it can take a variable if we are appending more content (via the more button at the bottom).
The page loads with a spinning “loading.gif” so if we are at this point we can hide it. Then we set up some bits to create the string announcing the results.
$("#loaderDiv").hide();
// array of names for the types of labels to return for results header
let type_labels = {
post: "Additional Resource",
portfolio: "Recommended Course",
resources: "Additional Resources",
courses: "Recommended Courses",
all: "Recommended Courses and Additional Resources"
};
// the resource type (either resources, courses, of both)
let rtype = $("input[name='results_type']:checked").val();
// now we can make a title string
let results_title = type_labels[rtype];
If none of the checkboxes are de-selected, it’s easy. The data is sitting in two arrays results_posts and results_courses for the two content types. If the selection is one of them, we just use the appropriate array; if it’s all content, we stitch them together, reverse sort by date, and use that data.
if ( $('#toggle_cats:checked').length > 0) {
// no categories to filter? use all data
if ( rtype == 'all' ) {
// both kinds of data, combine the results to one array
results_all = results_posts.concat(results_courses);
// sort by date
results_all.sortBy( function(){ return this.date } );
// reverse the order for newest first
results_all.reverse();
} else if (rtype == 'resources') {
results_all = results_posts;
} else {
results_all = results_courses;
}
The function we call for reverse sorting of the arrays by the data element is one of These Things I Found By Searching and It Works Even if I am Not Sure What it Does.
// --------------- array sorting magic ---------------
// This code is copyright 2012 by Gavin Kistner, !@phrogz.net
// It is covered under the license viewable at http://phrogz.net/JS/_ReuseLicense.txt
(function(){
if (typeof Object.defineProperty === 'function'){
try{Object.defineProperty(Array.prototype,'sortBy',{value:sb}); }catch(e){}
}
if (!Array.prototype.sortBy) Array.prototype.sortBy = sb;
function sb(f){
for (var i=this.length;i;){
var o = this[--i];
this[i] = [].concat(f.call(o,o,i),o);
}
this.sort(function(a,b){
for (var i=0,len=a.length;i
Back to the updating of results, if we are filtering by category, then it gets really interesting. Or messy.
We have to use some of those functions in the previous sections to get all of the category/taxonomy IDs represented by the checked boxes get_selected_cats_val(). Then we use a funky intersection function I found that can find out if array of taxonomy IDs for each item in the results we are walking through matches any in the array of selected categories. If we match, we add the item to the building array of ones we are to display.
Then we still have to run the sorting function again if we have mixed items from multiple taxonomy terms. And I even have a function (previous section) I can use to get the names of all selected checkbox category names as a string, so I can include that in the blue box header with the results.
} else {
// filter by selected categories
// get checkbox selection categories
selcats = get_selected_cats_val();
// reset results
results_all = [];
// filter the resources
if (rtype == 'all' || rtype == 'resources') {
results_posts.forEach(function(item) {
// check intersection of categories to selected checkboxes
intersection = item.categories.filter(x => selcats.includes(x));
if (intersection.length > 0 ) results_all.push(item);
});
}
// filter the courses
if (rtype == 'all' || rtype == 'courses') {
results_courses.forEach(function(item) {
// check intersection of categories to selected checkboxes
intersection = item.portfolio_category.filter(x => selcats.includes(x));
if (intersection.length > 0 ) results_all.push(item);
});
}
// sort by date
results_all.sortBy( function(){ return this.date } );
// reverse the order for newest first
results_all.reverse();
// include selected categories in the title
results_title += ' (in ' + get_selected_cats_names() + ')';
}
By now we should have the information we have filtered out of all the data to start iterating through to display. We have one check to see the upper limit of the number of items to walk through (in case we are near the end of the array), and a call to a helper function that forms the results header.
// limit check for number of results
let results_limit = Math.min( $("#results > li").length + loop, results_all.length);
// content for results header
let results_header = '
We then iterate through the array, and display either the compact text summary form or the rich media format (for the latter I added a bit of CSS to the output to put a numbered separator between results).
if (show_compact()) {
// compact, text only display
listclass = '';
for (var i = start; i < results_limit; i++) {
dt = new Date(Date.parse(results_all[i].date));
list += '
';
}
} else {
// full content plus media display
listclass = 'list-unstyled';
for (var i = start; i < results_limit; i++) {
dt = new Date(Date.parse(results_all[i].date));
list += '
And here we can now put all the results into the div where they are shown, or appending it if we are adding to ones already displayed. There are some checks at the end that determine if the more buttons show be shown.
if (start) {
// add results to existing list
$('#results').append(list);
// update count
$('.result_header span').text(results_limit);
// hide more button if no more to show
if (results_limit == results_all.length) $("#gimme").hide();
} else {
// add results to new list
$('#newest').html( results_header + '' + list + '' + results_header );
// check if we should show the more button
if (results_limit < results_all.length) {
$("#gimme").show();
} else {
$("#gimme").hide();
}
}
Lastly, for the full media format, a few more classes need to be added to divs that contain and iframe video and the iframe itself, this makes the videos responsively sized.
And this was fun to figure out, how to make the more button work all ajax like (though not really) to append more results. The trick here was using some CSS/jQuery to count the number of items currently in the list of outputs, so it knows the value to send to the update_results() function to append more.
To get really fancy, I also found some code to make it so the window scrolls back to where in the page the new content was added (without we are left at the tail end).
// add more results to output
$( "#more" ).click(function() {
// update based on current list length
update_results( $("#results > li").length );
// nifty trick to scroll to first newly added item
$("html, body").animate({ scrollTop: $('#item' + ($("#results > li").length - loop)).offset().top }, 1000);
});
Store Those Preferences in Local Storage
I am not sure if anyone will even notice this detail, bit given the current state of how prevalent (and some might say predatory) browser cookie tracking is, I'm excited to have implemented an approach which does what I might resorted before to cookies for.
And this is a key feature of the Navigator. If you saved all those settings from the form, each time your returned to the site, you'd have them preset for you.
Like I said, finding out about Local Storage was a bit like seeing inside the suitcase from Pulp Fiction. I perused a fewhow totutorials - and I found the stated reasons not to use it as irrelevant. It acts like a cookie (and is also deleted if you delete your browser history) but as far as I can sort out, there is no way that information is transmitted back to a web site. And all I am saving are some CSS IDs for saved checkboxes.
My form has a Save and Clear button to manage the storage. I added a click to confirm just to make it more clear to someone what is happening.
$("#saveboxes").click(function(){
// activate local storage
if ( confirm( "Save the selections of these categories for the next time you visit this site?" )){
store_local();
$("#storestatus").text('Selection data has been saved and will be preserved when you return to this site on this same device.');
} else {
return false;
}
});
$("#clearboxes").click(function(){
// clear local storage
if ( confirm( "Clear the selections saved on this device? The next time you return, all categories will be checked." )){
localStorage.clear();
$("#storestatus").text('Selection data has been deleted. Save again to preserve settings whenever you return to this site on this same device. ');
} else {
return false;
}
});
I ended up storing three variables (if I was doing this less incrementally, I could have condensed them a bit more)- the CSS ids for checked boxes, as well as the ids that represent the content type selection (radio buttons) and the display type, compact or media loaded (radio buttons).
function store_local() {
// store all topic categories
localStorage.setItem( "leadercats", get_selected_cats_id());
// store the content type
localStorage.setItem( "rtype", $("input[name='results_type']:checked")[0].id);
// store the display option
localStorage.setItem( "rformat", $("input[name='results_format']:checked")[0].id);
}
Everything is set up in an early function called as the page loads. We can test of Local Storage is available on the device and if we have one of our known variables floating around (if it is the rest should be there). Then we should restore the previous checked boxes with restore_selected_cats() otherwise we do the default settings set_default_checkboxes().
// set checkbox state for filter form, first try local storage saved settings
function setCheckboxes() {
// do we have local storage and for this site?
if ( typeof(Storage) !== "undefined" && localStorage.rtype ) {
// restore the checkboxes
restore_selected_cats();
} else {
// set radio buttons and check boxes to default ON
set_default_checkboxes();
}
}
Here are the default settings (if we don't have local storage, for extra grins we disable its buttons on the filter form).
function set_default_checkboxes() {
// set all the checkboxes to be ON
$('#results_all').attr('checked', 'checked');
$("#toggle_cats").prop('checked', true);
$('.leader-cat').prop('checked', true);
$('#compact_format').prop('checked', true);
// if localStorage not available, disable the save buttons
if ( typeof(Storage) == "undefined" ) {
$('#saveboxes').prop('disabled', true);
$('#clearboxes').prop('disabled', true);
}
}
But if we do have some saved settings, let's set them up:
function restore_selected_cats() {
// restore the content type radio button
if (localStorage.rtype) $('#' + localStorage.rtype).attr('checked', 'checked');
// restore the display format
if (localStorage.rformat) $('#' + localStorage.rformat).attr('checked', 'checked');
// restore topic category selections
if (localStorage.leadercats) {
localStorage.leadercats.split(",").forEach(function(boxid) {
$(boxid).prop('checked', true)
});
}
$("#storestatus").text('Selections set from stored data. Click "Save Selections" again to update.');
}
There's a few more small bits I've left out, if you want to see the whole dang script, I've got a link for ya. It's not your concise cool programmer code.
It was not a problem hitting the WordPress site for the API data as I was testing, but we don't really need to have every request going to the site for that, especially as the update frequency is not very high. The load time was maybe 10-15 seconds to get the two calls for JSON data back.
I knew all along I was planning to cache it. having the JSON files local on the site makes it load almost instantly. This is a crude PHP thing I wrote to call when it needs to be updated, and in production could be requested via a cron job. For the heck of it, it asks for a variable to be passed with a key code.
';
// make sure there is a file out there
if ( ( time() - filemtime($fname) ) > (3600 * $cache_life) ) {
// time to refresh the cache
echo '
refreshing cache for ' . $fname . '
';
// fetch some json and save locally
$json_contents = fetch_json( $link );
update_cache( $fname, $json_contents);
} else {
// updates can wait
echo '
No refresh needed for ' . $fname . '
';
}
} else {
echo '
No file present for ' . $fname . '
';
}
}
echo '
Fetching complete.
';
}
?>
CorrLeader JSON Fetcher
Checking json feeds...
Anyone Left in the Building?
This is an insanely long code heavy post, but it's my blog and I can blog what I want to. I wanted to capture the major parts and how it came together iteratively as I built it.
And this is of course, rather hard wired to the project and site I worked on. But this gives me a whole new leverage point where I could much more easily do one again, and I am seeing many more possibilities for thinking of ways to augment a WordPress site with a different means of accessing/scanning the contents.
For example, the idea to add a full media display came from a client wish to be able to have some cut and paste copy that could be used in emails with the organization, and this works really well so far in being able to do that. They could use the filters to find a category of content to promote, and use it to generate copy content.
With these tools inside my box, I am seeing all kinds of new magic ideas inside (and outside) of WordPress.